Nearest Neighbor is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions). It is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until function evaluation.
Training stage: The algorithm stores all the training data.
Testing stage: The algorithm compares the test data with the training data and returns the most similar data.
The algorithm is based on the assumption that the data points that are close to each other are similar. The similarity is calculated using a distance function, such as Euclidean distance, Manhattan distance, Minkowski distance, etc.
The algorithm is simple and easy to implement, but it is computationally expensive, especially when the training data is large. It is also sensitive to the curse of dimensionality, which means that the algorithm’s performance deteriorates as the number of dimensions increases.
Pseudocode
The pseudocode for the nearest neighbor algorithm is as follows:
For each test data point:
Calculate the distance between the test data point and all training data points.
Sort the distances in ascending order.
Select the nearest data points.
Determine the class of the nearest data points.
Assign the test data point to the nearest neighbor class.
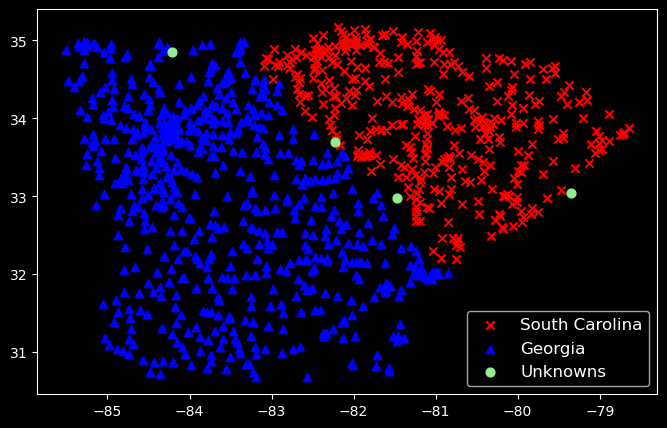
k-NN Algorithm
The k-NN algorithm is an extension of the nearest neighbor algorithm. Instead of returning the most similar data point, the algorithm returns the k most similar data points. The class of the test data is determined by the majority class of the k most similar data points.
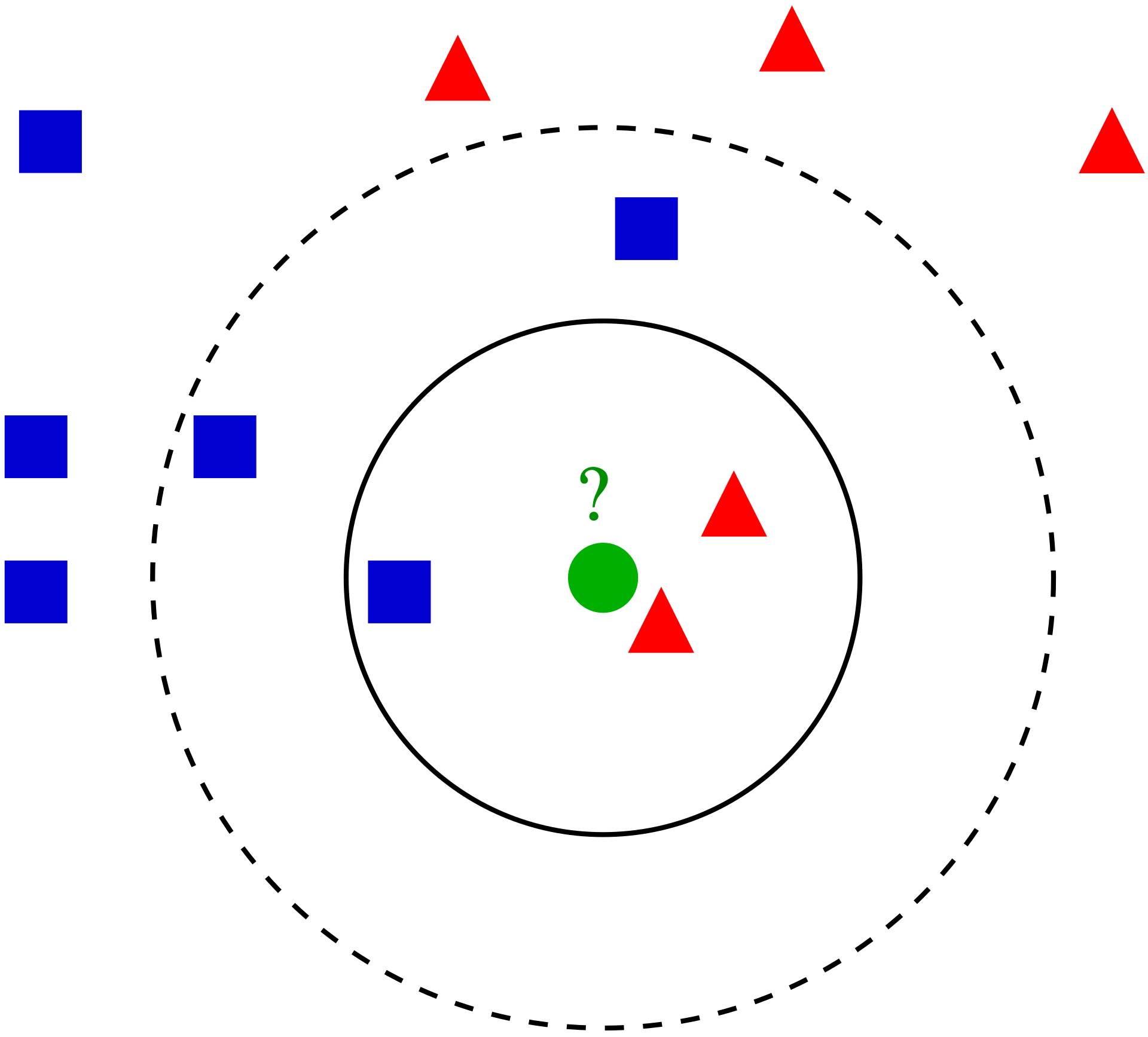
For example, in the figure below, the test sample (green dot) should be classified either to blue squares or to red triangles. If k = 3 (solid line circle) it is assigned to the red triangles because there are 2 triangles and only 1 square inside the inner circle. If k = 5 (dashed line circle) it is assigned to the blue squares (3 squares vs. 2 triangles inside the outer circle).
The k-NN algorithm is more robust than the nearest neighbor algorithm, as it reduces the noise in the data. However, it is computationally more expensive, as it requires storing and comparing more data points.
The k-NN algorithm is a simple and effective algorithm for classification and regression tasks. It is widely used in various fields, such as pattern recognition, image processing, and data mining.
k-NN Classication
Here is an example of how to implement the k-NN algorithm for classification in Python using the popular library scikit-learn:
In this example, we load the Iris dataset, split it into training and testing sets, create a k-NN classifier with k=3, fit the classifier to the training data, make predictions on the test data, and calculate the accuracy of the classifier.
import numpy as npfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# Load the iris datasetiris = load_iris()X = iris.datay = iris.target# Split the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create a k-NN classifier with k=3knn = KNeighborsClassifier(n_neighbors=3)# Fit the classifier to the training dataknn.fit(X_train, y_train)# Make predictions on the test datay_pred = knn.predict(X_test)# Calculate the accuracy of the classifieraccuracy = np.sum(y_pred == y_test) /len(y_test)print(f'Accuracy: {accuracy *100:.2f}%')
Accuracy: 100.00%
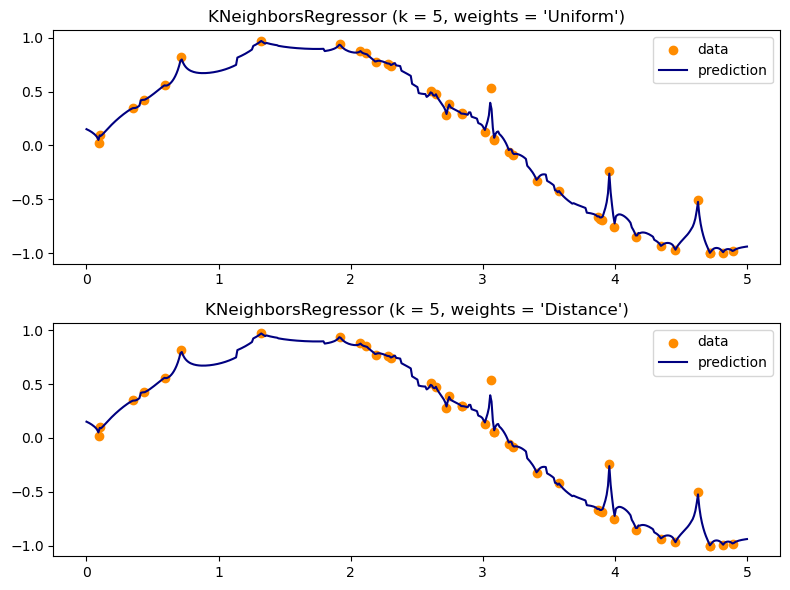
K-NN Regression
The k-NN algorithm can also be used for regression tasks. In k-NN regression, the output is the average of the k nearest neighbors’ values. The steps are similar to the k-NN classification algorithm, but instead of determining the class, the algorithm calculates the average value of the k nearest neighbors.
While Euclidean distance is the most commonly used distance metric in nearest neighbor algorithms, there are several alternative measures of similarity that can be used depending on the nature of the data and the specific application.
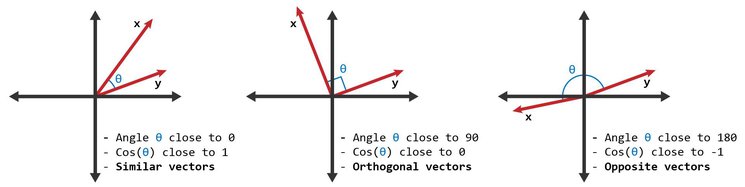
Cosine similarity measures the cosine of the angle between two non-zero vectors in an inner product space. It is particularly useful for high-dimensional data, such as text data represented as BOW vectors, where the magnitude of the vectors may not be as important as their direction.
The formula for cosine similarity between two vectors A and B is: \[
\text{Cosine Similarity} = \frac{A \cdot B}{||A|| \times ||B||}
\] where \(A \cdot B\) is the dot product of the vectors defined as \(A \cdot B = \sum_{i=1}^{n} A_i B_i\),
and \(||A||\) and \(||B||\) are the magnitudes of the vectors, calculated as \(||A|| = \sqrt{\sum_{i=1}^{n} A_i^2}\) and \(||B|| = \sqrt{\sum_{i=1}^{n} B_i^2}\).
Use 1 - Cosine Similarity to convert it into a distance metric if needed.
Cosine similarity ranges from -1 to 1, where 1 indicates that the vectors are identical, 0 indicates orthogonality (no similarity), and -1 indicates that the vectors are diametrically opposed.
As opposed to Euclidean distance, which is sensitive to the magnitude of the vectors, cosine similarity focuses on the orientation of the vectors, making it more suitable for certain applications like text analysis and recommendation systems.
In scikit-learn, you can use cosine similarity as a distance metric in k-NN as follows:
A classic toy example where cosine similarity works better than Euclidean distance is when magnitude doesn’t matter but direction does, especially in text or frequency/count vectors.
Imagine we have 3 short “documents” represented as word-count vectors in a 3-dimensional vocabulary: [“data”, “science”, “cat”]
Euclidean distance considers magnitude — so A and B look nearly as far apart as A and C, even though semantically A and B are very similar (both about data science) while C is completely different (about cats):
def euclidean(row1, row2):returnsum((row1 - row2) **2) **0.5print("A and B", euclidean(bow.loc['A'], bow.loc['B']))print("A and C", euclidean(bow.loc['A'], bow.loc['C']))
A and B 12.727922061357855
A and C 14.177446878757825
Cosine ignores magnitude and cares only about direction (pattern of word usage).