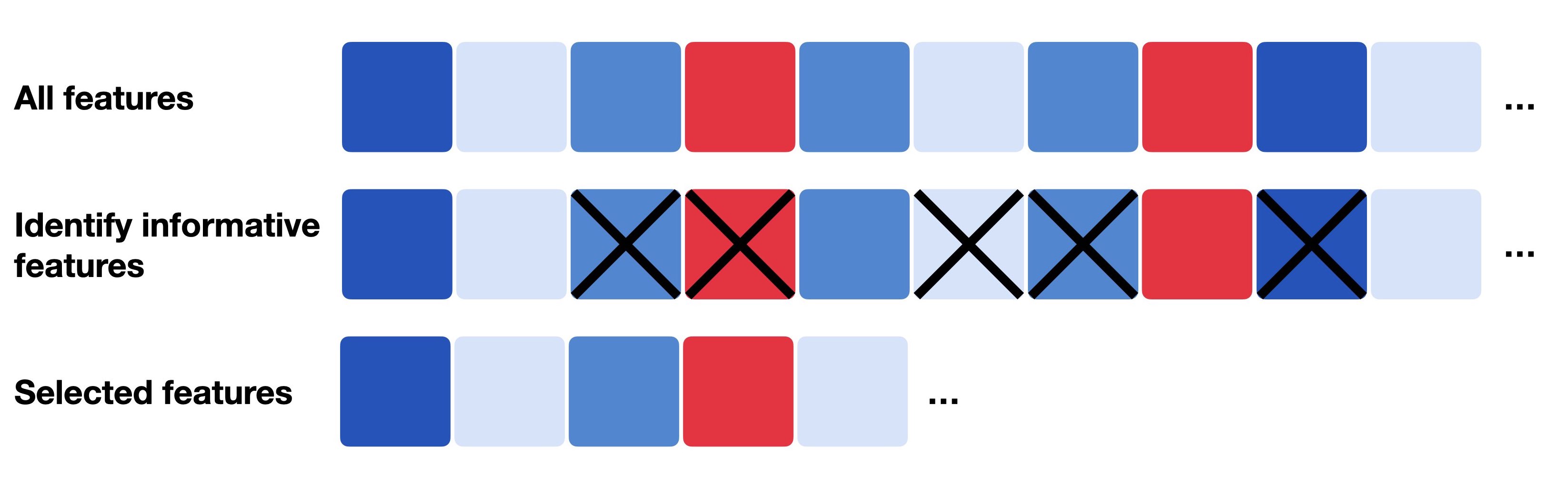
Feature selection is a crucial step in the machine learning pipeline. It involves selecting a subset of relevant features (variables, predictors) for use in model construction. The main goals of feature selection are to improve model performance, reduce overfitting, and decrease training time.
Curse of Dimensionality
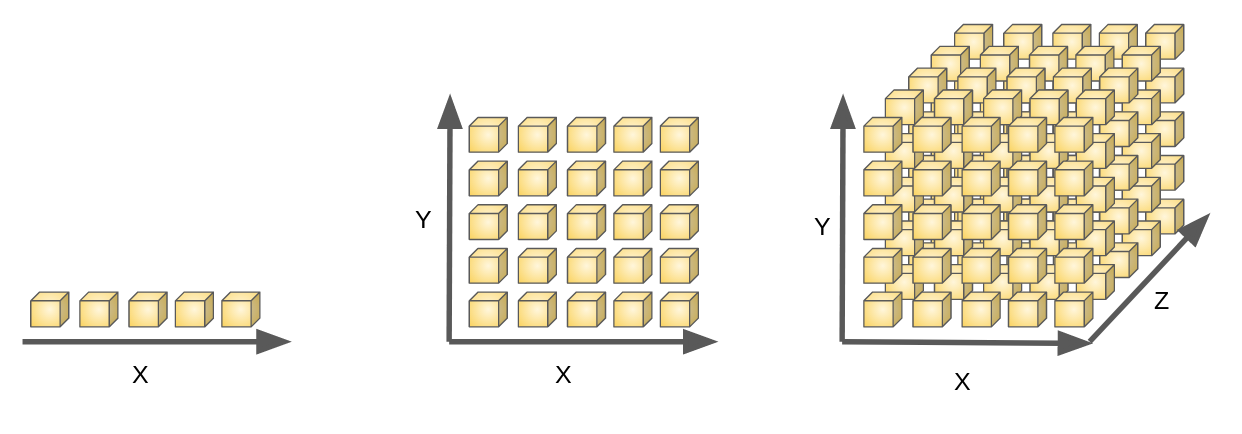
The “curse of dimensionality” refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings.
As the number of features (dimensions) increases, the volume of the space increases exponentially, leading to several challenges:
Data Sparsity: In high-dimensional spaces, data points become sparse. This sparsity makes it difficult to find meaningful patterns or relationships in the data, as the distance between points increases.
In other words, as the number of features increases, the amount of data needed to generalize accurately grows exponentially. This is because the volume of the search space increases exponentially with each new dimension added. To maintain the same level of data density, the number of required data points must also increase exponentially.
Increased Computational Cost: The computational cost of algorithms increases with the number of dimensions. Many machine learning algorithms become inefficient or infeasible to run as the dimensionality increases.
Overfitting: With more features, models can become overly complex and fit the noise in the training data rather than the underlying patterns. This leads to poor generalization to new data.
Distance Metrics Become Less Meaningful: In high-dimensional spaces, the concept of distance becomes less meaningful. For example, the difference between the nearest and farthest neighbor distances tends to diminish, making it harder to distinguish between points.
As a general rule of thumb, having at least 5 to 10 times as many observations as features is recommended to ensure reliable model performance. i.e.
\[ n \geq 5 \times d \]
where \(n\) is the number of observations and \(d\) is the number of features.
This isn’t a strict mathematical law. It’s a practical heuristic that helps ensure models can generalize well rather than memorize noise.
To mitigate the curse of dimensionality, feature selection techniques are employed to reduce the number of features while retaining the most informative ones. This helps improve model performance, reduce overfitting, and decrease computational costs.
This is why feature selection is essential in high-dimensional datasets to ensure that models can learn effectively without being overwhelmed by irrelevant or redundant information.
Correlations
Correlations are statistical measures that describe the strength and direction of the relationship between two variables. They help to identify how changes in one variable are associated with changes in another variable.
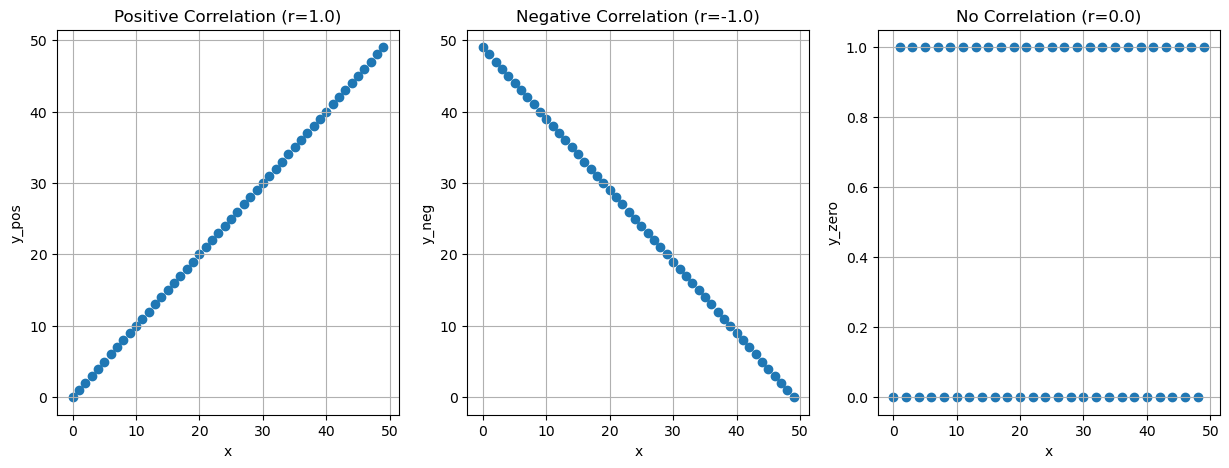
Positive correlation: If one variable increases, the other variable also increases.
Negative correlation: If one variable increases, the other variable decreases.
Zero correlation: There is no relationship between the two variables.
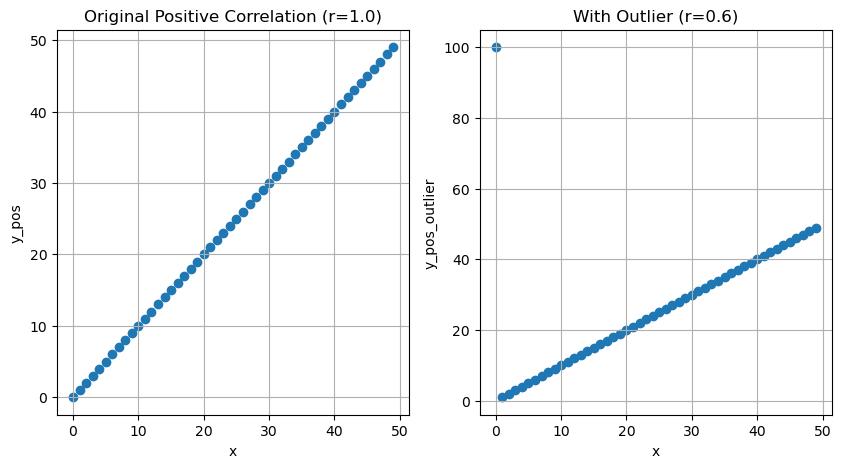
The correlation coefficient ranges from -1 to 1. A value of 1 indicates a perfect positive correlation, a value of -1 indicates a perfect negative correlation, and a value of 0 indicates no correlation.
There are several methods to compute the correlation between two variables. The two most common methods are the Pearson correlation coefficient and the Spearman correlation
Pearson Correlation Coefficient
The Pearson correlation coefficient measures the linear relationship between two variables. It ranges from -1 to 1.
where \(x_i\) and \(y_i\) are the \(i\)-th values of the two variables, $ _x$ and $ _y$ are the means of the two variables, and \(n\) is the number of values.
import pandas as pdfrom matplotlib import pyplot as plt n =50df = pd.DataFrame()df['x'] =list(range(n))df['y_pos'] = df['x']df['y_neg'] = df['x'].values[::-1]df['y_zero'] = [0if (i %2==0) else1for i inrange(n)]r_pos = df['x'].corr(df['y_pos'])r_neg = df['x'].corr(df['y_neg'])r_zero = df['x'].corr(df['y_zero'])fig, ax = plt.subplots(1, 3, figsize=(15, 5))ax[0].scatter(df['x'], df['y_pos'])ax[0].set_title(f'Positive Correlation (r={r_pos:.1f})')ax[0].set_xlabel('x')ax[0].set_ylabel('y_pos')ax[0].grid(True)ax[1].scatter(df['x'], df['y_neg'])ax[1].set_title(f'Negative Correlation (r={r_neg:.1f})')ax[1].set_xlabel('x')ax[1].set_ylabel('y_neg')ax[1].grid(True)ax[2].scatter(df['x'], df['y_zero'])ax[2].set_title(f'No Correlation (r={r_zero:.1f})')ax[2].set_xlabel('x')ax[2].set_ylabel('y_zero')ax[2].grid(True)
You can also compute the correlation between two columns of a DataFrame using the .corr() method.
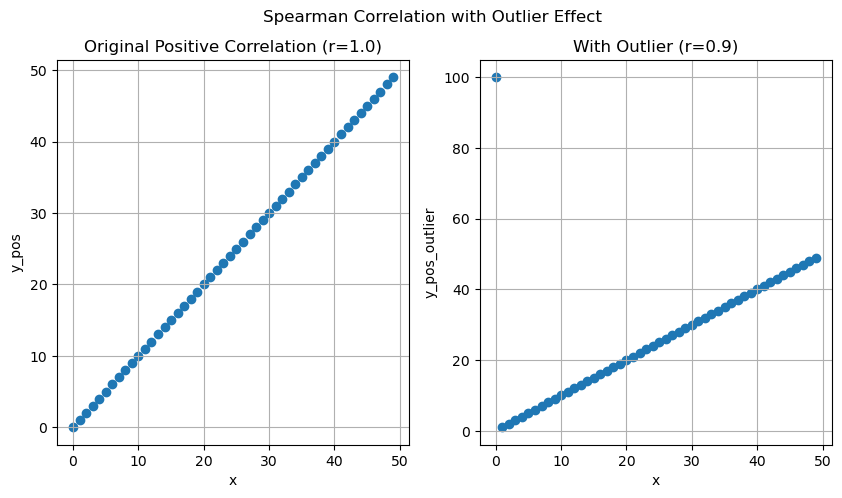
Spearman Correlation
The Spearman correlation coefficient measures the monotonic relationship between two variables. In simpler terms, it assesses how well the relationship between two variables can be described constantly increasing or decreasing, regardless of whether that relationship is linear.
Another way to think about it is that the Spearman correlation evaluates the relationship between the ranks of the data rather than the raw data itself. It creates a ranking of the values for each variable and then computes the Pearson correlation coefficient on these ranks.
Similar to Pearson correlation, coefficient, it ranges from -1 to 1.
Feature selection using correlations involves identifying and selecting features that have a strong correlation with the target variable while minimizing redundancy among the features themselves. Here are some common techniques for feature selection using correlations:
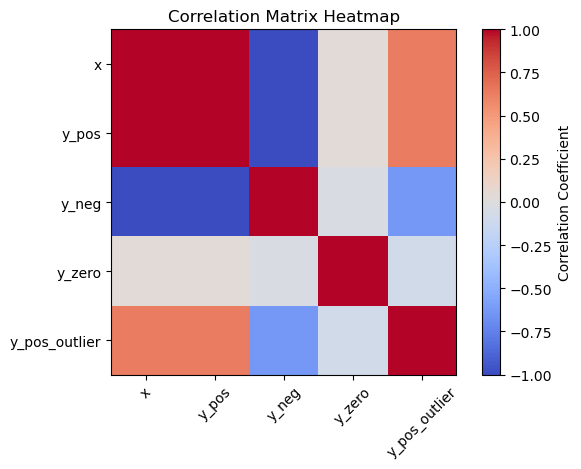
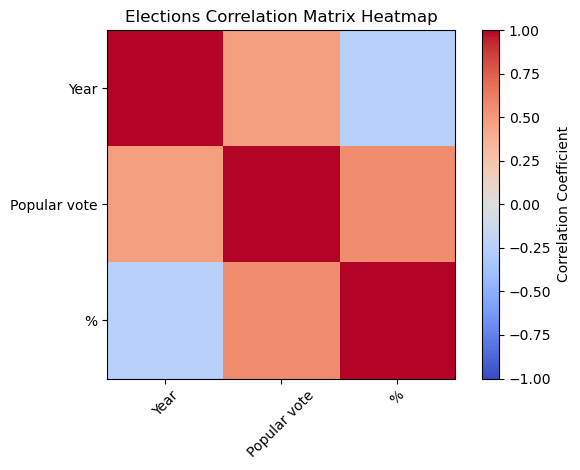
1. Correlation Matrix
A correlation matrix is a table that displays the correlation coefficients between multiple variables. It helps to visualize the relationships between features and the target variable.
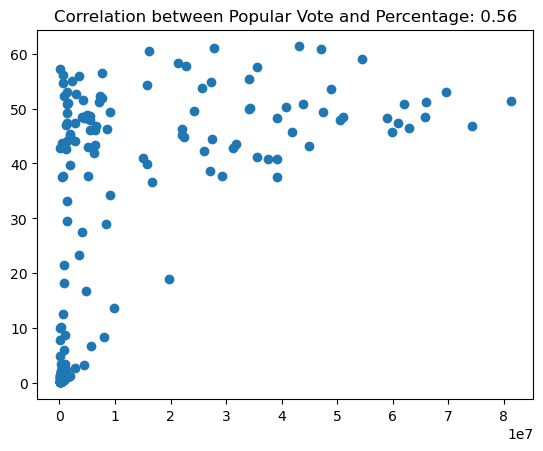
Once you have the correlation matrix, you can identify features that have a high correlation with the target variable (e.g., above a certain threshold like 0.5 or 0.7) and select them for your model.
2. Removing Highly Correlated Features
Highly correlated features can introduce multicollinearity, which can negatively impact model performance. To address this, you can remove one of the features from pairs of highly correlated features (e.g., correlation coefficient above 0.8 or 0.9).
3. Using Correlation Thresholds
You can set a correlation threshold to filter out features that do not meet a certain level of correlation with the target variable. For example, you might choose to keep only features with a correlation coefficient above 0.3 or below -0.3.