Up until this point, we have been working with individual rows of DataFrames. As data scientists, we often wish to investigate trends across a larger subset of our data. For example, we may want to compute some summary statistic (the mean, median, sum, etc.) for a group of rows in our DataFrame. To do this, we’ll use pandas GroupBy objects.
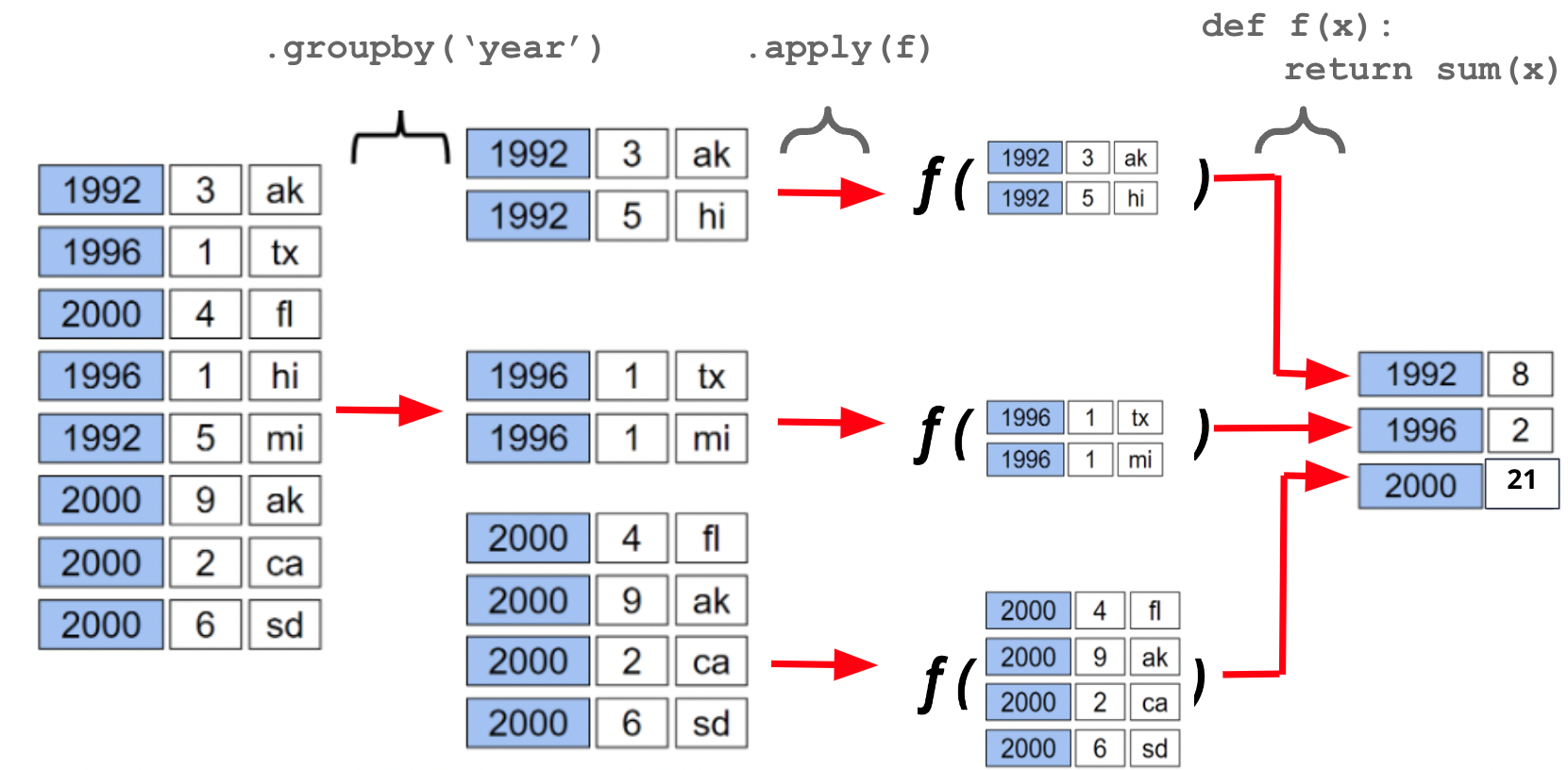
A groupby operation involves some combination of splitting a DataFrame into grouped subframes, applying a function, and combining the results.
For some arbitrary DataFrame df below, the code df.groupby("year").sum() does the following:
Splits the DataFrame into sub-DataFrames with rows belonging to the same year.
Applies the sum function to each column of each sub-DataFrame.
Combines the results of sum into a single DataFrame, indexed by year.
Let’s say we had baby names for all years in a single DataFrame names
import urllib.requestimport os.pathimport pandas as pd # Download data from the web directlydata_url ="https://www.ssa.gov/oact/babynames/names.zip"local_filename ="../data/names.zip"ifnot os.path.exists(local_filename): # if the data exists don't download againwith urllib.request.urlopen(data_url) as resp, open(local_filename, 'wb') as f: f.write(resp.read())# Load data without unzipping the fileimport zipfilenames = [] with zipfile.ZipFile(local_filename, "r") as zf: data_files = [f for f in zf.filelist if f.filename[-3:] =="txt"]def extract_year_from_filename(fn):returnint(fn[3:7])for f in data_files: year = extract_year_from_filename(f.filename)with zf.open(f) as fp: df = pd.read_csv(fp, names=["Name", "Sex", "Count"]) df["Year"] = year names.append(df)names = pd.concat(names)names
Name
Sex
Count
Year
0
Mary
F
7065
1880
1
Anna
F
2604
1880
2
Emma
F
2003
1880
3
Elizabeth
F
1939
1880
4
Minnie
F
1746
1880
...
...
...
...
...
31677
Zyell
M
5
2023
31678
Zyen
M
5
2023
31679
Zymirr
M
5
2023
31680
Zyquan
M
5
2023
31681
Zyrin
M
5
2023
2117219 rows × 4 columns
names.to_csv("../data/names.csv", index=False)
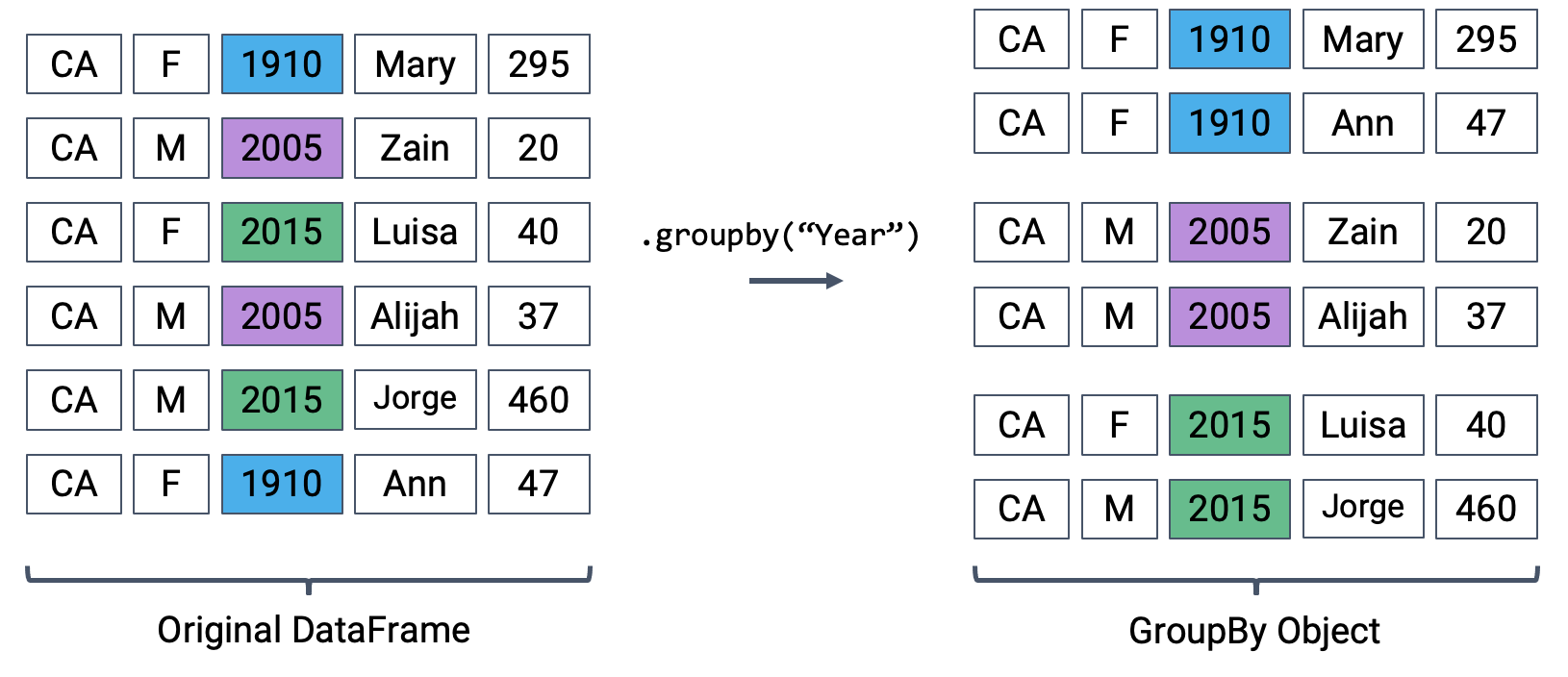
Now, if we wanted to aggregate all rows in names for a given year, we would need names.groupby("Year")
names.groupby("Year")
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f7a30b64bb0>
What does this strange output mean? Calling .groupby has generated a GroupBy object. You can imagine this as a set of “mini” sub-DataFrames, where each subframe contains all of the rows from names that correspond to a particular year.
The diagram below shows a simplified view of names to help illustrate this idea.
We can’t work with a GroupBy object directly – that is why you saw that strange output earlier, rather than a standard view of a DataFrame. To actually manipulate values within these “mini” DataFrames, we’ll need to call an aggregation method. This is a method that tells pandas how to aggregate the values within the GroupBy object. Once the aggregation is applied, pandas will return a normal (now grouped) DataFrame.
Aggregation functions (.min(), .max(), .mean(), .sum(), etc.) are the most common way to work with GroupBy objects. These functions are applied to each column of a “mini” grouped DataFrame. We end up with a new DataFrame with one aggregated row per subframe. Let’s see this in action by finding the sum of all counts for each year in names – this is equivalent to finding the number of babies born in each year.
names.groupby("Year").sum().head(5)
Count
Year
1880
201484
1881
192690
1882
221533
1883
216944
1884
243461
We can relate this back to the diagram we used above. Remember that the diagram uses a simplified version of names, which is why we see smaller values for the summed counts.
Calling .agg has condensed each subframe back into a single row. This gives us our final output: a DataFrame that is now indexed by "Year", with a single row for each unique year in the original names DataFrame.
You may be wondering: where did the "State", "Sex", and "Name" columns go? Logically, it doesn’t make sense to sum the string data in these columns (how would we add “Mary” + “Ann”?). Because of this, pandas will simply omit these columns when it performs the aggregation on the DataFrame. Since this happens implicitly, without the user specifying that these columns should be ignored, it’s easy to run into troubling situations where columns are removed without the programmer noticing. It is better coding practice to select only the columns we care about before performing the aggregation.
# Same result, but now we explicitly tell pandas to only consider the "Count" column when summingnames.groupby("Year")[["Count"]].sum().head(5)
Count
Year
1880
201484
1881
192690
1882
221533
1883
216944
1884
243461
There are many different aggregations that can be applied to the grouped data. The primary requirement is that an aggregation function must:
Take in a Series of data (a single column of the grouped subframe)
Return a single value that aggregates this Series
Because of this fairly broad requirement, pandas offers many ways of computing an aggregation.
In-built Python operations – such as sum, max, and min – are automatically recognized by pandas.
# What is the maximum count for each name in any year?names.groupby("Name")[["Count"]].max().head()
Count
Name
Aaban
16
Aabha
9
Aabid
6
Aabidah
5
Aabir
5
# What is the minimum count for each name in any year?names.groupby("Name")[["Count"]].min().head()
Count
Name
Aaban
5
Aabha
5
Aabid
5
Aabidah
5
Aabir
5
# What is the average count for each name across all years?names.groupby("Name")[["Count"]].mean().head()
Count
Name
Aaban
10.000000
Aabha
6.375000
Aabid
5.333333
Aabidah
5.000000
Aabir
5.000000
pandas also offers a number of in-built functions for aggregation. Some examples include:
.sum()
.max()
.min()
.mean()
.first()
.last()
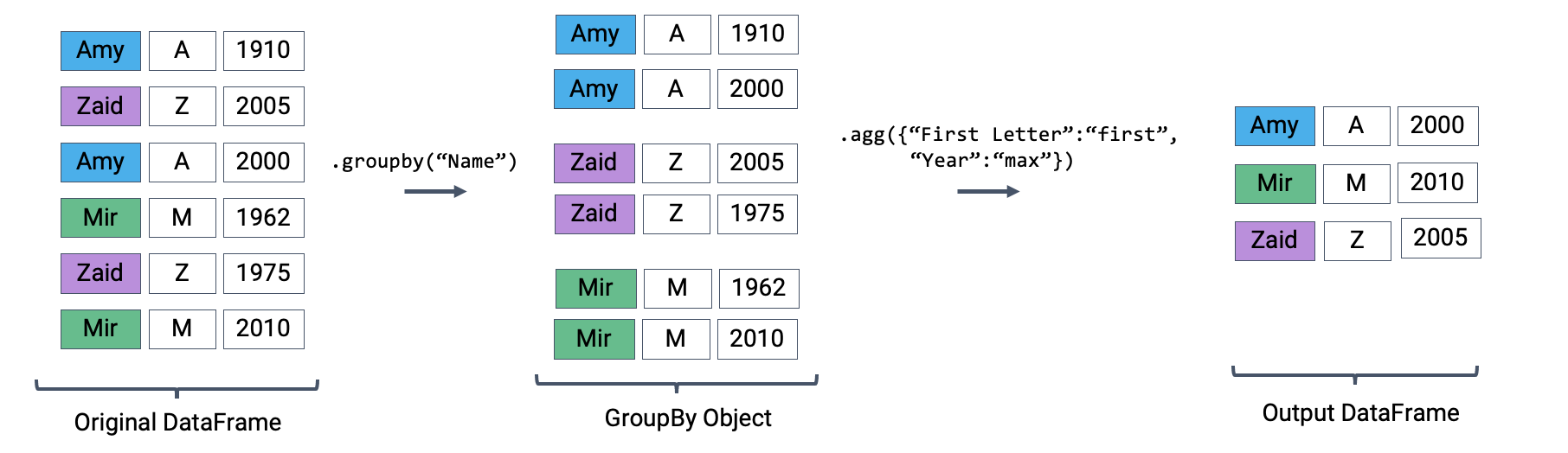
The latter two entries in this list – "first" and "last" – are unique to pandas. They return the first or last entry in a subframe column. Why might this be useful? Consider a case where multiple columns in a group share identical information. To represent this information in the grouped output, we can simply grab the first or last entry, which we know will be identical to all other entries.
Let’s illustrate this with an example. Say we add a new column to names that contains the first letter of each name.
# Imagine we had an additional column, "First Letter". We'll explain this code next weeknames["First Letter"] = names["Name"].apply(lambda x: x[0])# We construct a simplified DataFrame containing just a subset of columnsnames_new = names[["Name", "First Letter", "Year"]]names_new.head()
Name
First Letter
Year
0
Mary
M
1880
1
Anna
A
1880
2
Emma
E
1880
3
Elizabeth
E
1880
4
Minnie
M
1880
If we form groups for each name in the dataset, "First Letter" will be the same for all members of the group. This means that if we simply select the first entry for "First Letter" in the group, we’ll represent all data in that group.
We can use a dictionary to apply different aggregation functions to each column during grouping.
We can also define aggregation functions of our own! This can be done using either a def or lambda statement. Again, the condition for a custom aggregation function is that it must take in a Series and output a single scalar value.
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Input In [2], in <cell line: 4>() 1defratio_to_peak(series):
2return series.iloc[-1]/max(series)
----> 4names.groupby("Name")[["Year", "Count"]].apply(ratio_to_peak)
NameError: name 'names' is not defined
Note
lambda functions are a special type of function that can be defined in a single line. They are also often refered to as “anonymous” functions because these functions don’t have a name. They are useful for simple functions that are not used elsewhere in your code.
# Alternatively, using lambdanames.groupby("Name")[["Year", "Count"]].agg(lambda s: s.iloc[-1]/max(s))
Year
Count
Name
Aaban
1.0
0.375000
Aabha
1.0
0.555556
Aabid
1.0
1.000000
Aabidah
1.0
1.000000
Aabir
1.0
1.000000
...
...
...
Zyvion
1.0
1.000000
Zyvon
1.0
1.000000
Zyyanna
1.0
1.000000
Zyyon
1.0
1.000000
Zzyzx
1.0
1.000000
101338 rows × 2 columns
Aggregation with lambda Functions
We’ll work with the elections DataFrame again.
import pandas as pdurl ="https://raw.githubusercontent.com/fahadsultan/csc272/main/data/elections.csv"elections = pd.read_csv(url)elections.head(5)
Year
Candidate
Party
Popular vote
Result
%
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
1
1824
John Quincy Adams
Democratic-Republican
113142
win
42.789878
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
3
1828
John Quincy Adams
National Republican
500897
loss
43.796073
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
What if we wish to aggregate our DataFrame using a non-standard function – for example, a function of our own design? We can do so by combining .agg with lambda expressions.
Let’s first consider a puzzle to jog our memory. We will attempt to find the Candidate from each Party with the highest % of votes.
A naive approach may be to group by the Party column and aggregate by the maximum.
elections.groupby("Party").agg(max).head(10)
Year
Candidate
Popular vote
Result
%
Party
American
1976
Thomas J. Anderson
873053
loss
21.554001
American Independent
1976
Lester Maddox
9901118
loss
13.571218
Anti-Masonic
1832
William Wirt
100715
loss
7.821583
Anti-Monopoly
1884
Benjamin Butler
134294
loss
1.335838
Citizens
1980
Barry Commoner
233052
loss
0.270182
Communist
1932
William Z. Foster
103307
loss
0.261069
Constitution
2016
Michael Peroutka
203091
loss
0.152398
Constitutional Union
1860
John Bell
590901
loss
12.639283
Democratic
2020
Woodrow Wilson
81268924
win
61.344703
Democratic-Republican
1824
John Quincy Adams
151271
win
57.210122
This approach is clearly wrong – the DataFrame claims that Woodrow Wilson won the presidency in 2020.
Why is this happening? Here, the max aggregation function is taken over every column independently. Among Democrats, max is computing:
The most recent Year a Democratic candidate ran for president (2020)
The Candidate with the alphabetically “largest” name (“Woodrow Wilson”)
The Result with the alphabetically “largest” outcome (“win”)
Instead, let’s try a different approach. We will:
Sort the DataFrame so that rows are in descending order of %
Group by Party and select the first row of each sub-DataFrame
While it may seem unintuitive, sorting elections by descending order of % is extremely helpful. If we then group by Party, the first row of each groupby object will contain information about the Candidate with the highest voter %.
elections_sorted_by_percent.groupby("Party").agg(lambda x : x.iloc[0]).head(10)# Equivalent to the below code# elections_sorted_by_percent.groupby("Party").agg('first').head(10)
Year
Candidate
Popular vote
Result
%
Party
American
1856
Millard Fillmore
873053
loss
21.554001
American Independent
1968
George Wallace
9901118
loss
13.571218
Anti-Masonic
1832
William Wirt
100715
loss
7.821583
Anti-Monopoly
1884
Benjamin Butler
134294
loss
1.335838
Citizens
1980
Barry Commoner
233052
loss
0.270182
Communist
1932
William Z. Foster
103307
loss
0.261069
Constitution
2008
Chuck Baldwin
199750
loss
0.152398
Constitutional Union
1860
John Bell
590901
loss
12.639283
Democratic
1964
Lyndon Johnson
43127041
win
61.344703
Democratic-Republican
1824
Andrew Jackson
151271
loss
57.210122
Here’s an illustration of the process:
Notice how our code correctly determines that Lyndon Johnson from the Democratic Party has the highest voter %.
More generally, lambda functions are used to design custom aggregation functions that aren’t pre-defined by Python. The input parameter x to the lambda function is a GroupBy object. Therefore, it should make sense why lambda x : x.iloc[0] selects the first row in each groupby object.
In fact, there’s a few different ways to approach this problem. Each approach has different tradeoffs in terms of readability, performance, memory consumption, complexity, etc. We’ve given a few examples below.
Note: Understanding these alternative solutions is not required. They are given to demonstrate the vast number of problem-solving approaches in pandas.
# Using the idxmax functionbest_per_party = elections.loc[elections.groupby('Party')['%'].idxmax()]best_per_party.head(5)
Year
Candidate
Party
Popular vote
Result
%
22
1856
Millard Fillmore
American
873053
loss
21.554001
115
1968
George Wallace
American Independent
9901118
loss
13.571218
6
1832
William Wirt
Anti-Masonic
100715
loss
7.821583
38
1884
Benjamin Butler
Anti-Monopoly
134294
loss
1.335838
127
1980
Barry Commoner
Citizens
233052
loss
0.270182
# Using the .drop_duplicates functionbest_per_party2 = elections.sort_values('%').drop_duplicates(['Party'], keep='last')best_per_party2.head(5)
Year
Candidate
Party
Popular vote
Result
%
148
1996
John Hagelin
Natural Law
113670
loss
0.118219
164
2008
Chuck Baldwin
Constitution
199750
loss
0.152398
110
1956
T. Coleman Andrews
States' Rights
107929
loss
0.174883
147
1996
Howard Phillips
Taxpayers
184656
loss
0.192045
136
1988
Lenora Fulani
New Alliance
217221
loss
0.237804
Other GroupBy Features
There are many aggregation methods we can use with .agg. Some useful options are:
.mean: creates a new DataFrame with the mean value of each group
.sum: creates a new DataFrame with the sum of each group
.max and .min: creates a new DataFrame with the maximum/minimum value of each group
.first and .last: creates a new DataFrame with the first/last row in each group
.size: creates a new Series with the number of entries in each group
.count: creates a new DataFrame with the number of entries, excluding missing values.
Note the slight difference between .size() and .count(): while .size() returns a Series and counts the number of entries including the missing values, .count() returns a DataFrame and counts the number of entries in each column excluding missing values. Here’s an example:
You might recall that the value_counts() function in the previous note does something similar. It turns out value_counts() and groupby.size() are the same, except value_counts() sorts the resulting Series in descending order automatically.
df["letter"].value_counts()
C 3
A 2
B 1
Name: letter, dtype: int64
hese (and other) aggregation functions are so common that pandas allows for writing shorthand. Instead of explicitly stating the use of .agg, we can call the function directly on the GroupBy object.
For example, the following are equivalent:
elections.groupby("Candidate").agg(mean)
elections.groupby("Candidate").mean()
There are many other methods that pandas supports. You can check them out on the pandas documentation.
What’s going on here? In this example, we’ve defined our filtering function, \(\text{f}\), to be lambda sf: sf["%"].max() < 45. This filtering function will find the maximum "%" value among all entries in the grouped sub-DataFrame, which we call sf. If the maximum value is less than 45, then the filter function will return True and all rows in that grouped sub-DataFrame will appear in the final output DataFrame.
Examine the DataFrame above. Notice how, in this preview of the first 9 rows, all entries from the years 1860 and 1912 appear. This means that in 1860 and 1912, no candidate in that year won more than 45% of the total vote.
You may ask: how is the groupby.filter procedure different to the boolean filtering we’ve seen previously? Boolean filtering considers individual rows when applying a boolean condition. For example, the code elections[elections["%"] < 45] will check the "%" value of every single row in elections; if it is less than 45, then that row will be kept in the output. groupby.filter, in contrast, applies a boolean condition across all rows in a group. If not all rows in that group satisfy the condition specified by the filter, the entire group will be discarded in the output.