import pandas as pdimport warnings warnings.filterwarnings("ignore")data = pd.read_csv("../data/Shark Tank US dataset.csv")data = data[data.columns[:30]]data['Got Deal'] = data['Got Deal'].astype(bool)data.head(2)
Season Number
Startup Name
Episode Number
Pitch Number
Season Start
Season End
Original Air Date
Industry
Business Description
Company Website
...
Got Deal
Total Deal Amount
Total Deal Equity
Deal Valuation
Number of Sharks in Deal
Investment Amount Per Shark
Equity Per Shark
Royalty Deal
Advisory Shares Equity
Loan
0
1
AvaTheElephant
1
1
9-Aug-09
5-Feb-10
9-Aug-09
Health/Wellness
Ava The Elephant - Baby and Child Care
http://www.avatheelephant.com/
...
True
50000.0
55.0
90909.0
1.0
50000.0
55.0
NaN
NaN
NaN
1
1
MrTod'sPieFactory
1
2
9-Aug-09
5-Feb-10
9-Aug-09
Food and Beverage
Mr. Tod's Pie Factory - Specialty Food
http://whybake.com/
...
True
460000.0
50.0
920000.0
2.0
230000.0
25.0
NaN
NaN
NaN
2 rows × 30 columns
Joint Frequency
The joint frequency of two events is the number of times they both occur in a given number of trials.
In pandas, we can calculate the joint frequency of two events by using the crosstab function.
pd.crosstab(data['Industry'], data['Got Deal'])
Got Deal
False
True
Industry
Automotive
4
13
Business Services
21
19
Children/Education
45
78
Electronics
9
7
Fashion/Beauty
98
128
Fitness/Sports/Outdoors
48
79
Food and Beverage
116
180
Green/CleanTech
5
6
Health/Wellness
27
40
Lifestyle/Home
83
163
Liquor/Alcohol
5
5
Media/Entertainment
9
17
Pet Products
24
33
Software/Tech
31
38
Travel
6
5
Uncertain/Other
8
15
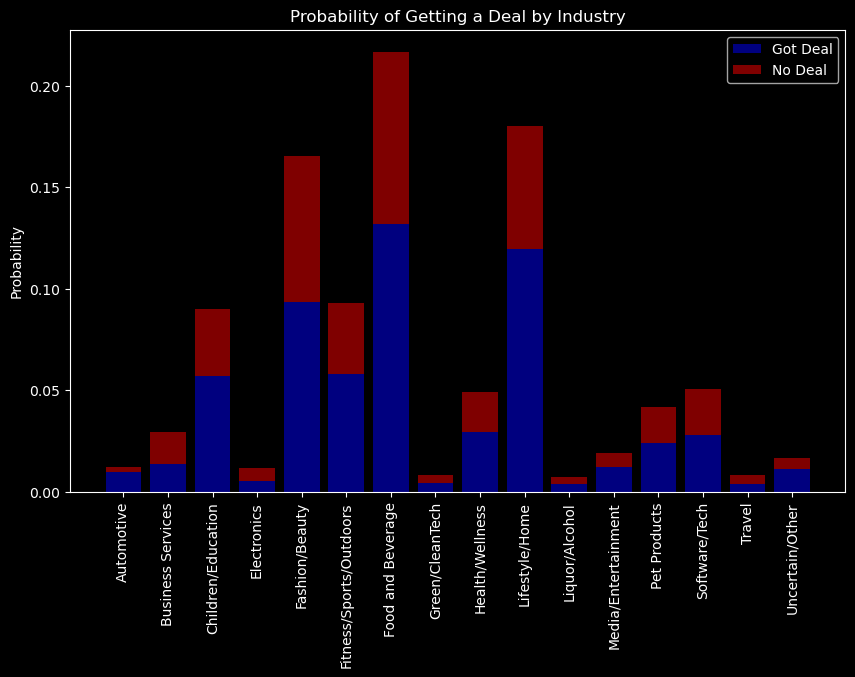
Joint Probability \(P(A, B)\)
Joint probability is the probability of two events occurring together.The joint probability is usually denoted by \(P(A, B)\), which is shorthand for \(P(A \wedge B)\) read as Probability of \(A\) AND \(B\).
Note that \(P(A, B) = P(B, A)\) since \(A \wedge B = B \wedge A\).
For example, if we are rolling two dice, the joint probability is the probability of rolling a 1 on the first die and a 2 on the second die.
In Data Science, we rarely know the true joint probability. Instead, we estimate the joint probability from data. We will talk more about this when we talk about Statistics.
Because most data sets are multi-dimensional i.e. involving multiple random variables, we can sometimes find ourselves in a situation where we want to know the joint probability \(P(A, B)\) of two random variables \(A\) and \(B\) but we don’t know \(P(A)\) or \(P(B)\). In such cases, we compute the marginal probability of one variable from joint probability over multiple random variables.
Marginalizing is the process of summing over one or more variables (say B) to get the probability of another variable (say A). This summing takes place over the joint probability table.
\[ P(A) = \sum_{b \in \Omega_B} P(A, B=b) \]
joint_prob
Got Deal
False
True
Industry
Automotive
0.002930
0.009524
Business Services
0.015385
0.013919
Children/Education
0.032967
0.057143
Electronics
0.006593
0.005128
Fashion/Beauty
0.071795
0.093773
Fitness/Sports/Outdoors
0.035165
0.057875
Food and Beverage
0.084982
0.131868
Green/CleanTech
0.003663
0.004396
Health/Wellness
0.019780
0.029304
Lifestyle/Home
0.060806
0.119414
Liquor/Alcohol
0.003663
0.003663
Media/Entertainment
0.006593
0.012454
Pet Products
0.017582
0.024176
Software/Tech
0.022711
0.027839
Travel
0.004396
0.003663
Uncertain/Other
0.005861
0.010989
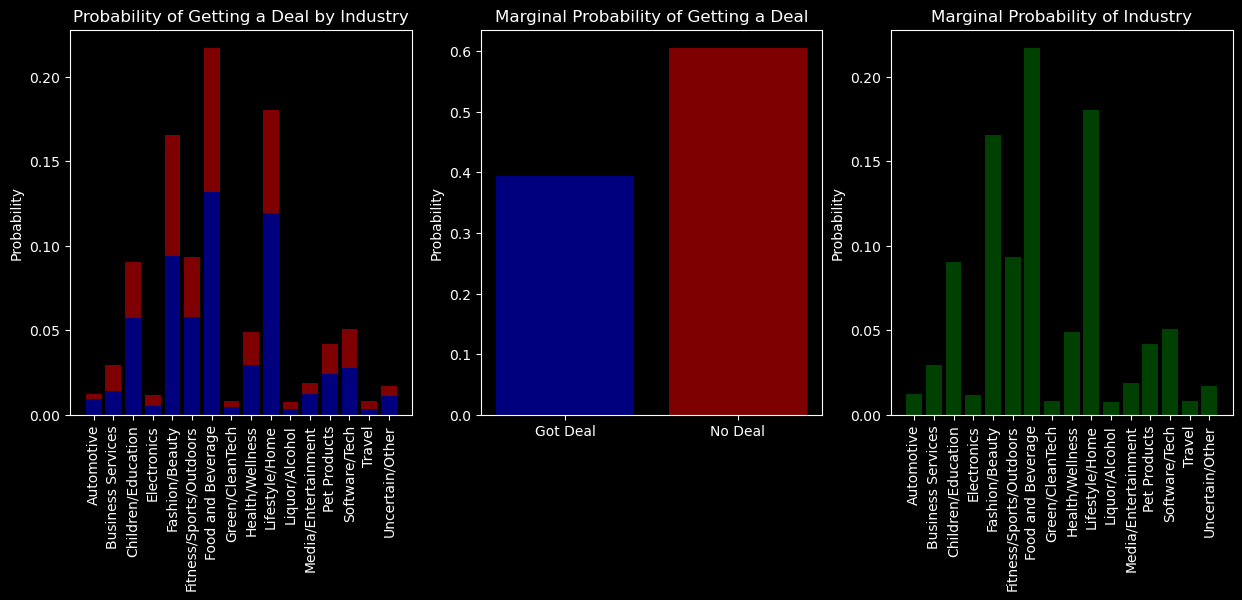
# marginal probability of getting a dealmarginal_prob = joint_prob.sum(axis=0)marginal_prob
# marginal probability of industrymarginal_prob = joint_prob.sum(axis=1)marginal_prob
Industry
Automotive 0.012454
Business Services 0.029304
Children/Education 0.090110
Electronics 0.011722
Fashion/Beauty 0.165568
Fitness/Sports/Outdoors 0.093040
Food and Beverage 0.216850
Green/CleanTech 0.008059
Health/Wellness 0.049084
Lifestyle/Home 0.180220
Liquor/Alcohol 0.007326
Media/Entertainment 0.019048
Pet Products 0.041758
Software/Tech 0.050549
Travel 0.008059
Uncertain/Other 0.016850
dtype: float64
fig, axs = plt.subplots(1, 3, figsize=(15, 5))axs[0].bar(joint_prob.index, joint_prob[True], label='Got Deal', color='blue', alpha=0.5)axs[0].bar(joint_prob.index, joint_prob[False], bottom=joint_prob[True], label='No Deal', color='red', alpha=0.5)axs[0].set_xticklabels(joint_prob.index, rotation=90)axs[0].set_ylabel('Probability')axs[0].set_title('Probability of Getting a Deal by Industry')# Marginal probability of getting a dealmarginal_prob_deal = joint_prob.sum(axis=0)axs[1].bar(marginal_prob_deal.index, marginal_prob_deal, color=['blue', 'red'], alpha=0.5)axs[1].set_xticks([0, 1])axs[1].set_xticklabels(['Got Deal', 'No Deal'])axs[1].set_ylabel('Probability')axs[1].set_title('Marginal Probability of Getting a Deal')# Marginal probability of industrymarginal_prob_industry = joint_prob.sum(axis=1)axs[2].bar(joint_prob.index, marginal_prob_industry, color='green', alpha=0.5)axs[2].set_xticklabels(joint_prob.index, rotation=90)axs[2].set_ylabel('Probability')axs[2].set_title('Marginal Probability of Industry')
Text(0.5, 1.0, 'Marginal Probability of Industry')
As we look at new concepts in probability, it is important to stay mindful of i) what the probability sums to ii) what are the dimensions of the table that represents the probability.
You can see from the cell below that the dimensions of marginal probability table is the length of the range of the variable.
You can see from the code below that both the computed marginal probabilities in add up to 1.
Independent Random Variables
Random variables can be either independent or dependent. If two random variables are independent, then the value of one random variable does not affect the value of the other random variable.
For example, if we are rolling two dice, we can use two random variables to represent the numbers that we roll. The two random variables are independent because the value of one die does not affect the value of the other die. If two random variables are dependent, then the value of one random variable does affect the value of the other random variable. For example, if we are measuring the temperature and the humidity, we can use two random variables to represent the temperature and the humidity. The two random variables are dependent because the temperature affects the humidity and the humidity affects the temperature.
More formally, two random variables \(X\) and \(Y\) are independent if and only if \(P(X, Y) = P(X) \cdot P(Y)\).
# Test for independence of Industry and Got Dealprob_deal = joint_prob.sum(axis=0)prob_industry = joint_prob.sum(axis=1)prob_deal