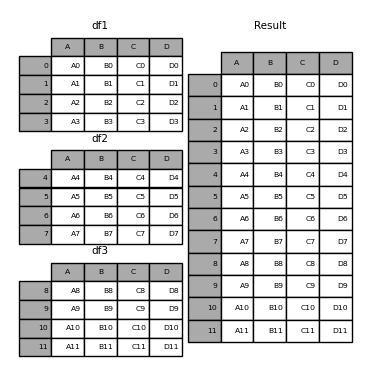
Another way to combine DataFrames is to concatenate them. Concatenation is a bit different from joining. When we join two DataFrames, we are combining them horizontally – that is, we are adding new columns to an existing DataFrame. Concatenation, on the other hand, is generally a vertical operation – we are adding new rows to an existing DataFrame.
pd.concat is the pandas method used to concatenate DataFrames together. It takes as input a list of DataFrames to be concatenated and returns a new DataFrame containing all of the rows from each input DataFrame in the input list.
Let’s say we wanted to concatenate data from two different years in babynames. We can do so using the pd.concat method.
import pandas as pd url_template ="https://raw.githubusercontent.com/fahadsultan/csc272/main/data/names/yob%s.txt"data_list = []for year inrange(1880, 2023): url = url_template % year data = pd.read_csv(url, header=None, names=['name', 'sex', 'count']) data['year'] = year data_list.append(data)all_data = pd.concat(data_list)all_data
name
sex
count
year
0
Mary
F
7065
1880
1
Anna
F
2604
1880
2
Emma
F
2003
1880
3
Elizabeth
F
1939
1880
4
Minnie
F
1746
1880
...
...
...
...
...
31910
Zuberi
M
5
2022
31911
Zydn
M
5
2022
31912
Zylon
M
5
2022
31913
Zymeer
M
5
2022
31914
Zymeire
M
5
2022
2085158 rows × 4 columns
Merging DataFrames
When working on data science projects, we’re unlikely to have absolutely all the data we want contained in a single DataFrame – a real-world data scientist needs to grapple with data coming from multiple sources. If we have access to multiple datasets with related information, we can merge two or more tables into a single DataFrame.
To put this into practice, we’ll revisit the elections dataset.
elections.head(5)
Year
Candidate
Party
Popular vote
Result
%
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
1
1824
John Quincy Adams
Democratic-Republican
113142
win
42.789878
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
3
1828
John Quincy Adams
National Republican
500897
loss
43.796073
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
Say we want to understand the popularity of the names of each presidential candidate in 2020. To do this, we’ll need the combined data of namesandelections.
We’ll start by creating a new column containing the first name of each presidential candidate. This will help us join each name in elections to the corresponding name data in names.
# Here, we'll only consider `names` data from 2020names_2020 = names[names["Year"]==2020]names_2020.head()
Name
Sex
Count
Year
First Letter
0
Olivia
F
17641
2020
O
1
Emma
F
15656
2020
E
2
Ava
F
13160
2020
A
3
Charlotte
F
13065
2020
C
4
Sophia
F
13036
2020
S
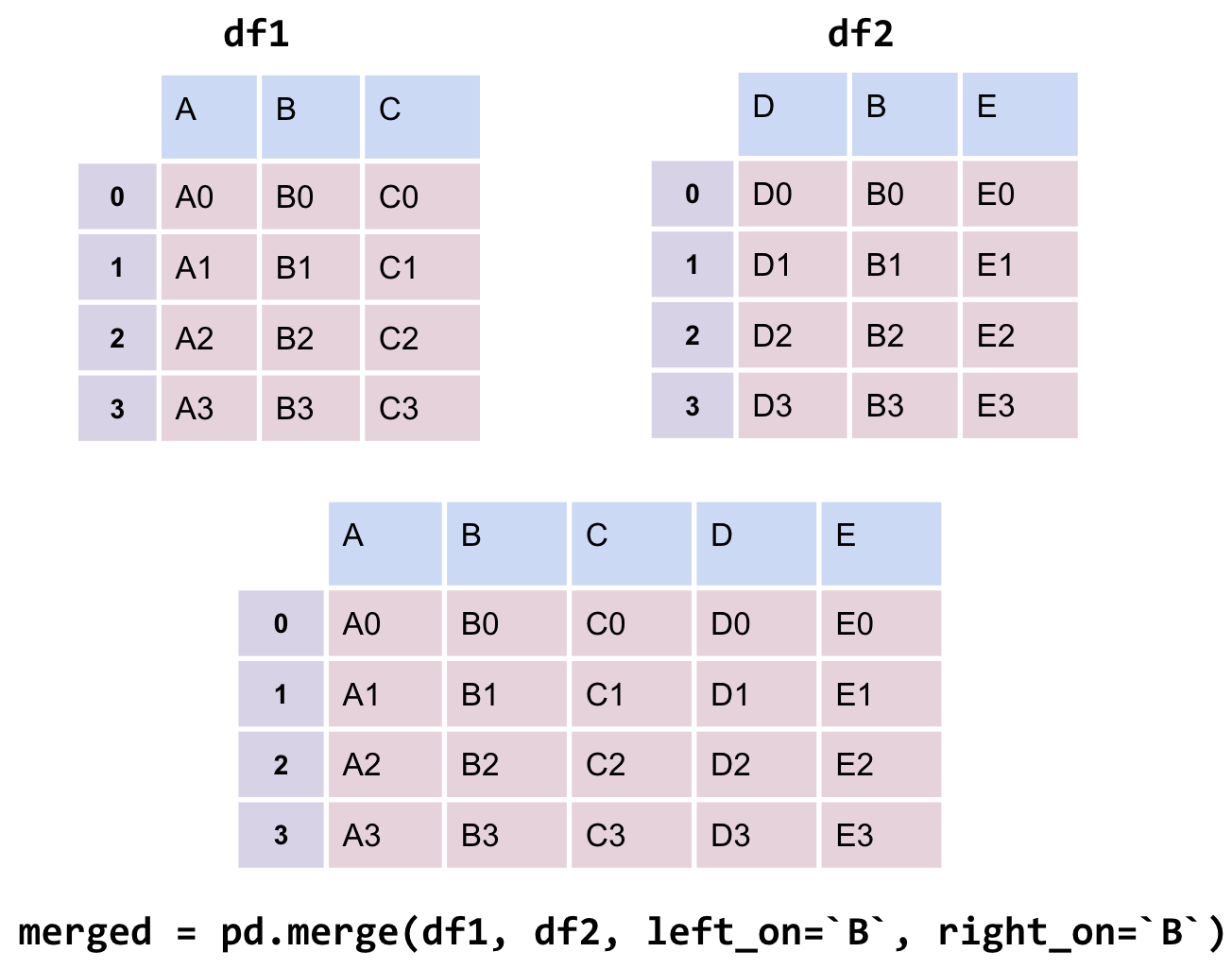
Now, we’re ready to merge the two tables. pd.merge is the pandas method used to merge DataFrames together.
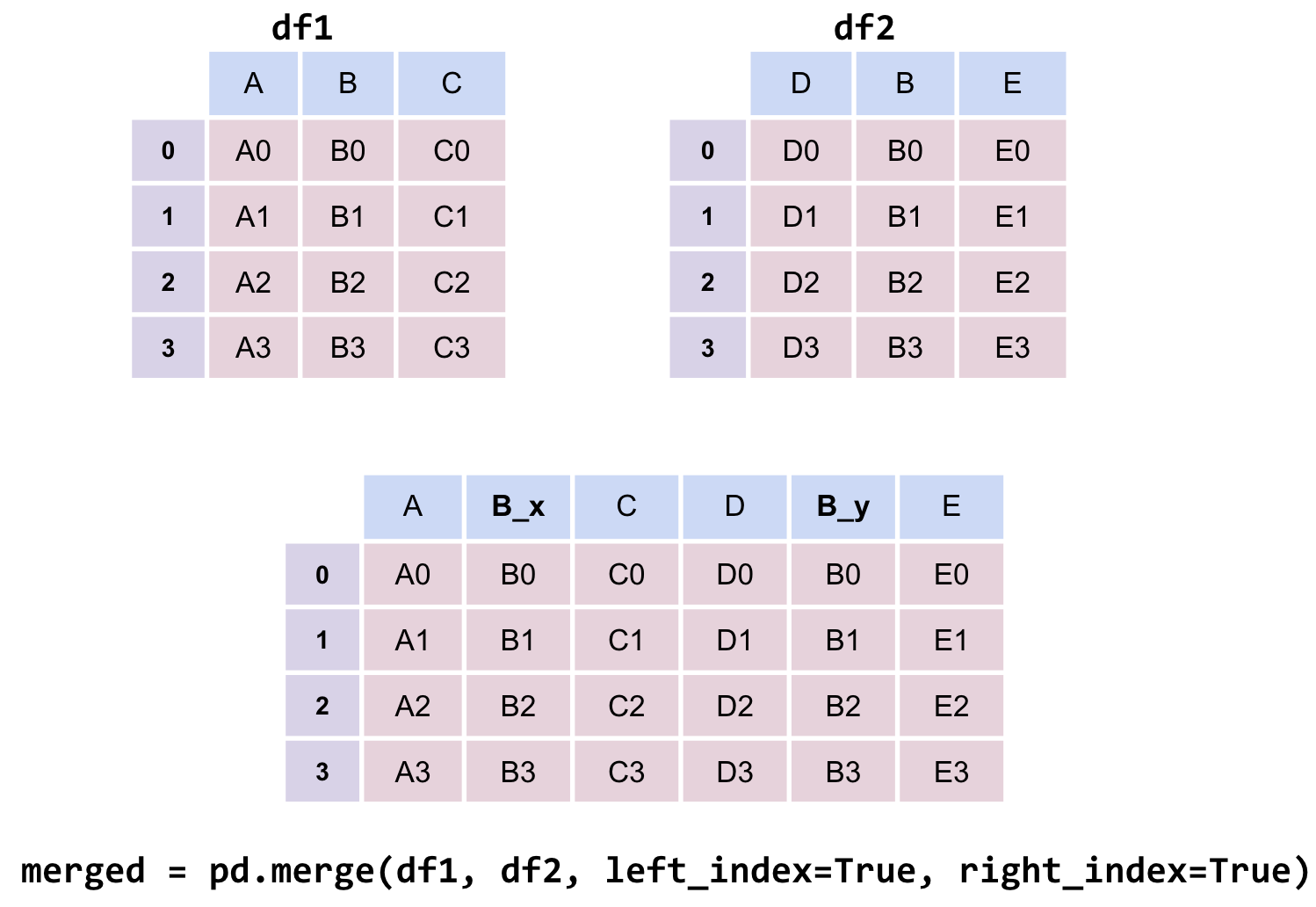
merged = pd.merge(left = elections, right = names_2020, \ left_on ="First Name", right_on ="Name")merged.head()# Notice that pandas automatically specifies `Year_x` and `Year_y` # when both merged DataFrames have the same column name to avoid confusion
Year_x
Candidate
Party
Popular vote
Result
%
First Name
Name
Sex
Count
Year_y
First Letter
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
Andrew
Andrew
F
12
2020
A
1
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
Andrew
Andrew
M
6036
2020
A
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
Andrew
Andrew
F
12
2020
A
3
1828
Andrew Jackson
Democratic
642806
win
56.203927
Andrew
Andrew
M
6036
2020
A
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
Andrew
Andrew
F
12
2020
A
Let’s take a closer look at the parameters:
left and right parameters are used to specify the DataFrames to be merge.
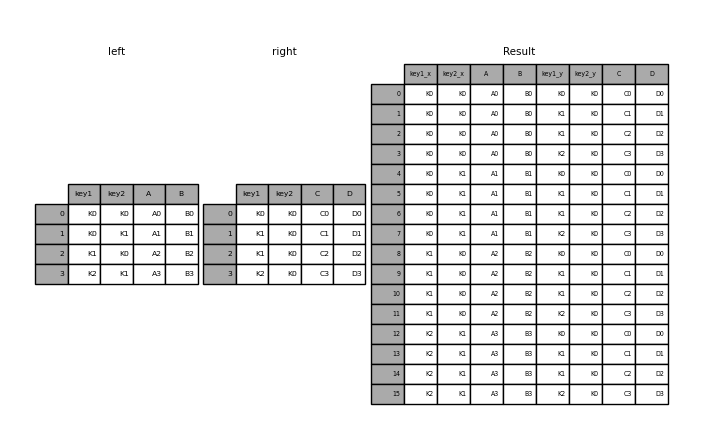
left_on and right_on parameters are assigned to the string names of the columns to be used when performing the merge. These two on parameters tell pandas what values should act as pairing keys to determine which rows to merge across the DataFrames. We’ll talk more about this idea of a pairing key next lecture.
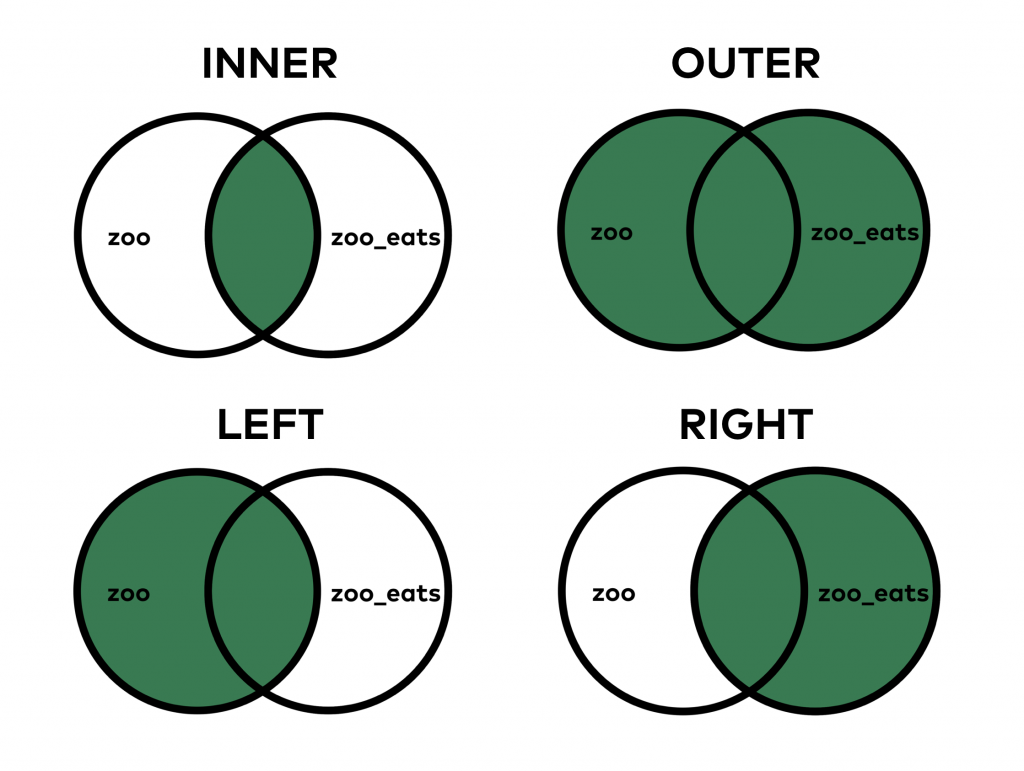
Types of Merges
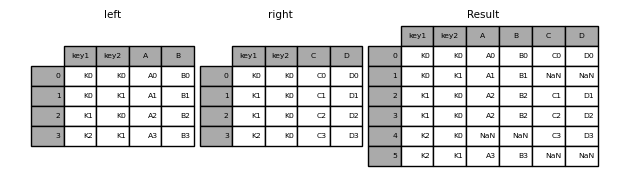
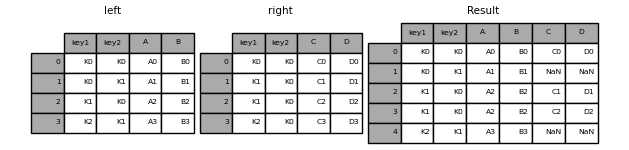
There are five types of merges in pandas. The type of merge is determined by the how parameter in the pd.merge method. The five types of merges are:
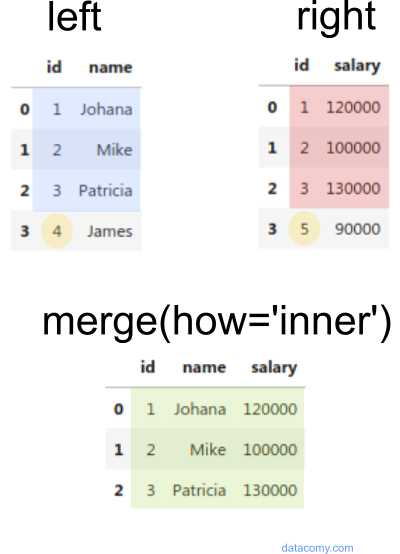
Inner Merge (Default) how='inner': This is the default type of merge in pandas. It returns only the rows that have matching values in both DataFrames.
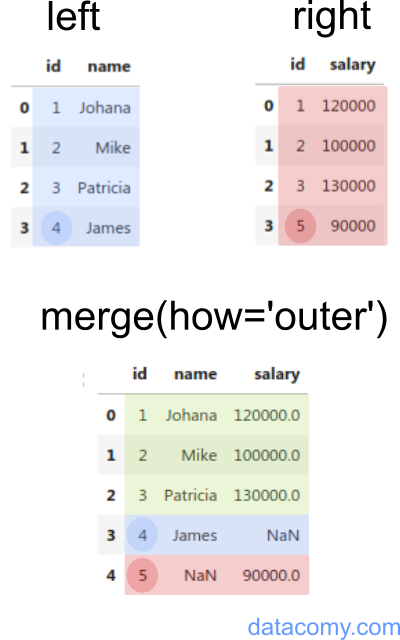
Outer Mergehow='outer': This merge returns all rows from both DataFrames. If a row has no match in the other DataFrame, the missing values are filled with NaN.
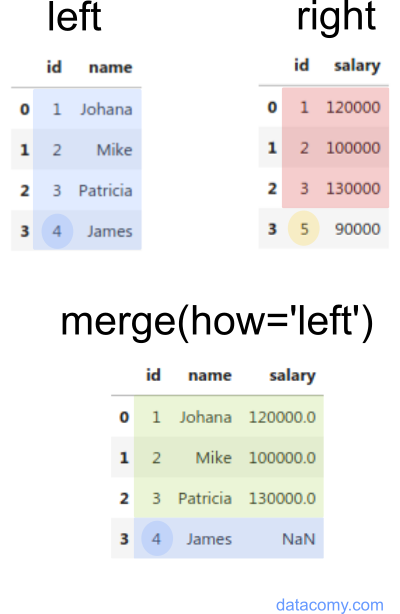
Left Mergehow='left': This merge returns all rows from the left DataFrame and the matched rows from the right DataFrame. The result is NaN for the right DataFrame if there is no match.
Right Mergehow='right': This merge returns all rows from the right DataFrame and the matched rows from the left DataFrame. The result is NaN for the left DataFrame if there is no match.
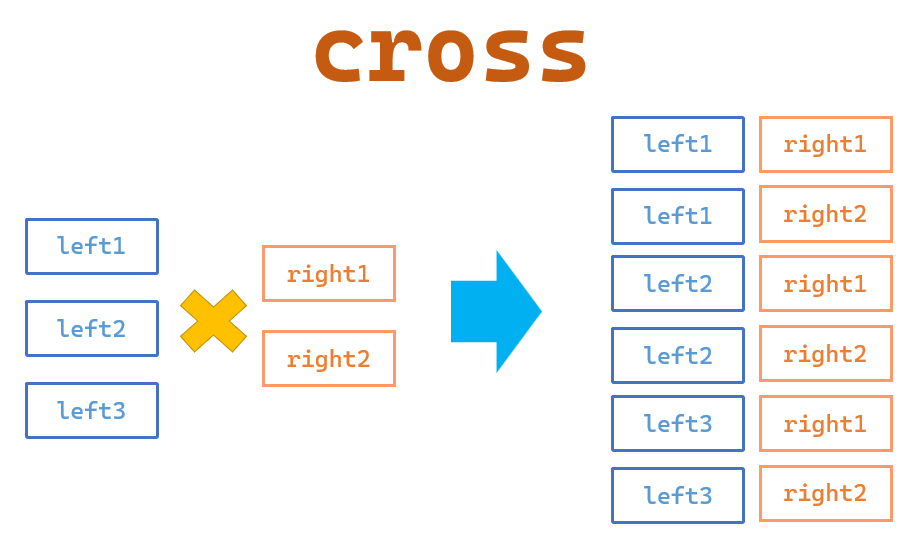
Cross Mergehow='cross': This merge returns the Cartesian product of the two DataFrames. That is, it returns all possible combinations of rows from both DataFrames.