Data Science and Machine Learning
Machine Learning involves creating mathematical models that can learn from and make predictions or decisions based on data.
Mathematical Models
A mathematical model in machine learning is typically represented as a function or a set of equations that describe the relationship between one set of columns (features) and another set of columns (target variable).
\[ y = f(X) \]
Where:
\(y\) is the target variable (output) implemented as a vector of length
n_samplesi.e. \(y \in \mathbb{R}^n\)\(X\) is the feature set (input) implemented as a matrix of shape
(n_samples, n_features)i.e. \(X \in \mathbb{R}^{n \times m}\)\(f\) is the model or set of equations that maps inputs to outputs
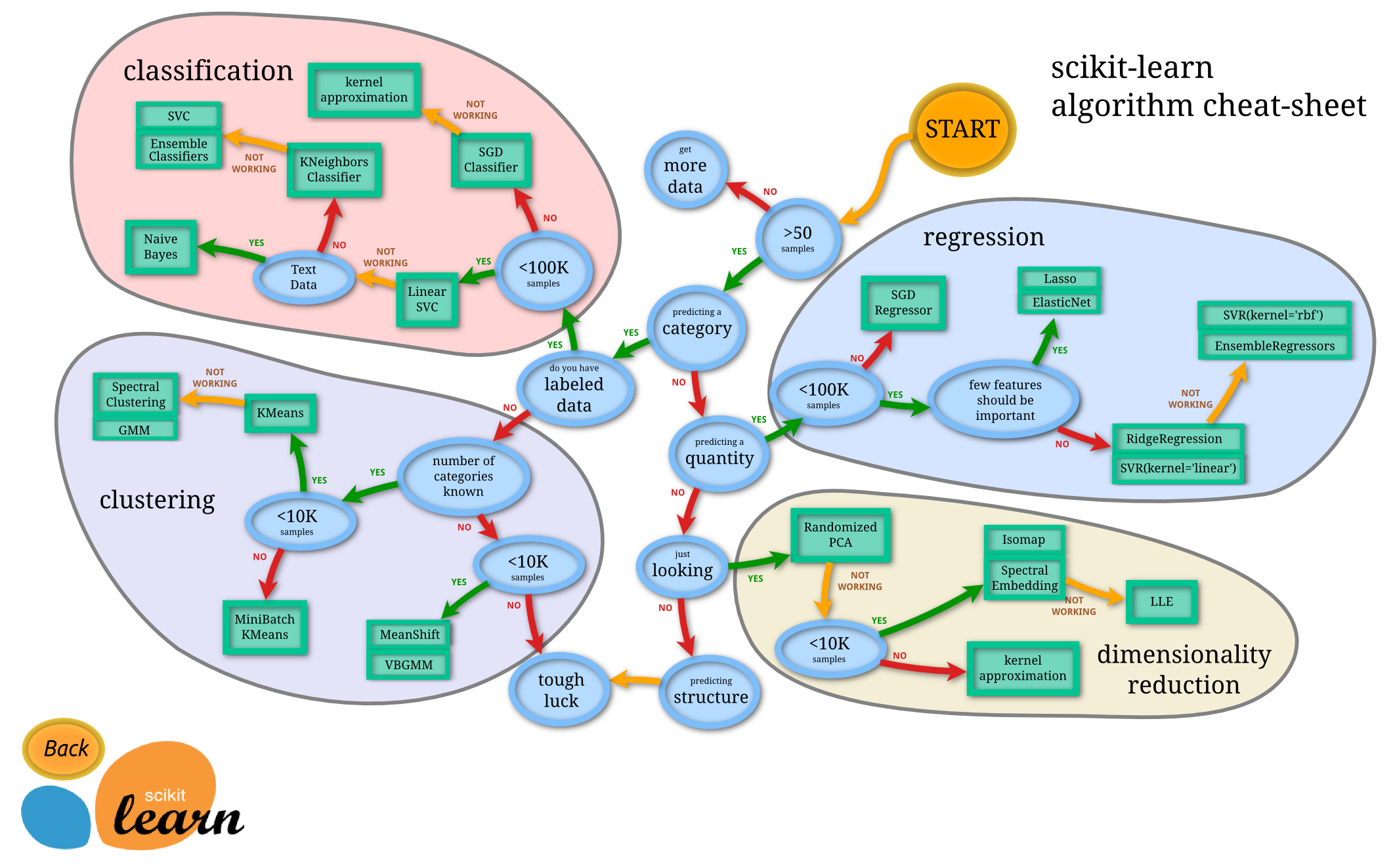
Problems in Machine Learning
There are primarily two types of machine learning:
Supervised Learning
Unsupervised Learning

Supervised Learning
In supervised learning, the model is trained on a labeled dataset, which means that each training example is paired with an output label. The goal is to learn a mapping from inputs to outputs. Common algorithms include linear regression, decision trees, and support vector machines.
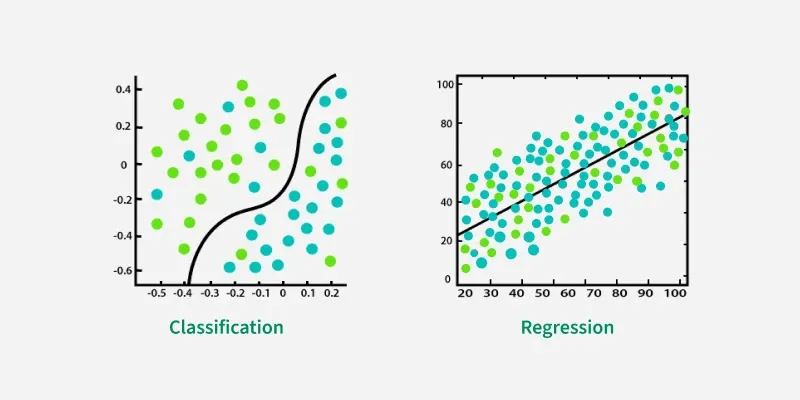
Classification
Classification involves predicting a discrete label or category for a given input. Examples include spam detection in emails and image recognition.
Regression
Regression involves predicting a continuous value based on input features. Examples include predicting house prices or stock prices.
Unsupervised Learning
In unsupervised learning, the model is trained on data without labeled responses. The goal is to find hidden patterns or intrinsic structures in the input data. Common algorithms include clustering (like K-means) and dimensionality reduction (like PCA).
Clustering
Clustering involves grouping a set of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups. Examples include customer segmentation and image compression.
Dimensionality Reduction
Dimensionality reduction involves reducing the number of random variables under consideration, by obtaining a set of principal variables. Examples include feature selection and feature extraction techniques.

Sklearn
Scikit-learn (sklearn) is a popular Python library for machine learning that provides simple and efficient tools for data mining and data analysis. It is built on top of NumPy, SciPy, and Matplotlib.