elections.loc[0, 'Candidate']Extracting and Dropping values
To extract a subset of values, we can use .loc[] or .iloc[] with row and column indices and labels respectively.

The .loc[] method is used to access a group of rows and columns by labels or a boolean array.
.loc[row_labels, col_labels]
The .loc operator selects rows and columns in a DataFrame by their row and column label(s), respectively. The row labels (commonly referred to as the indices) are the bold text on the far left of a DataFrame, while the column labels are the column names found at the top of a DataFrame.
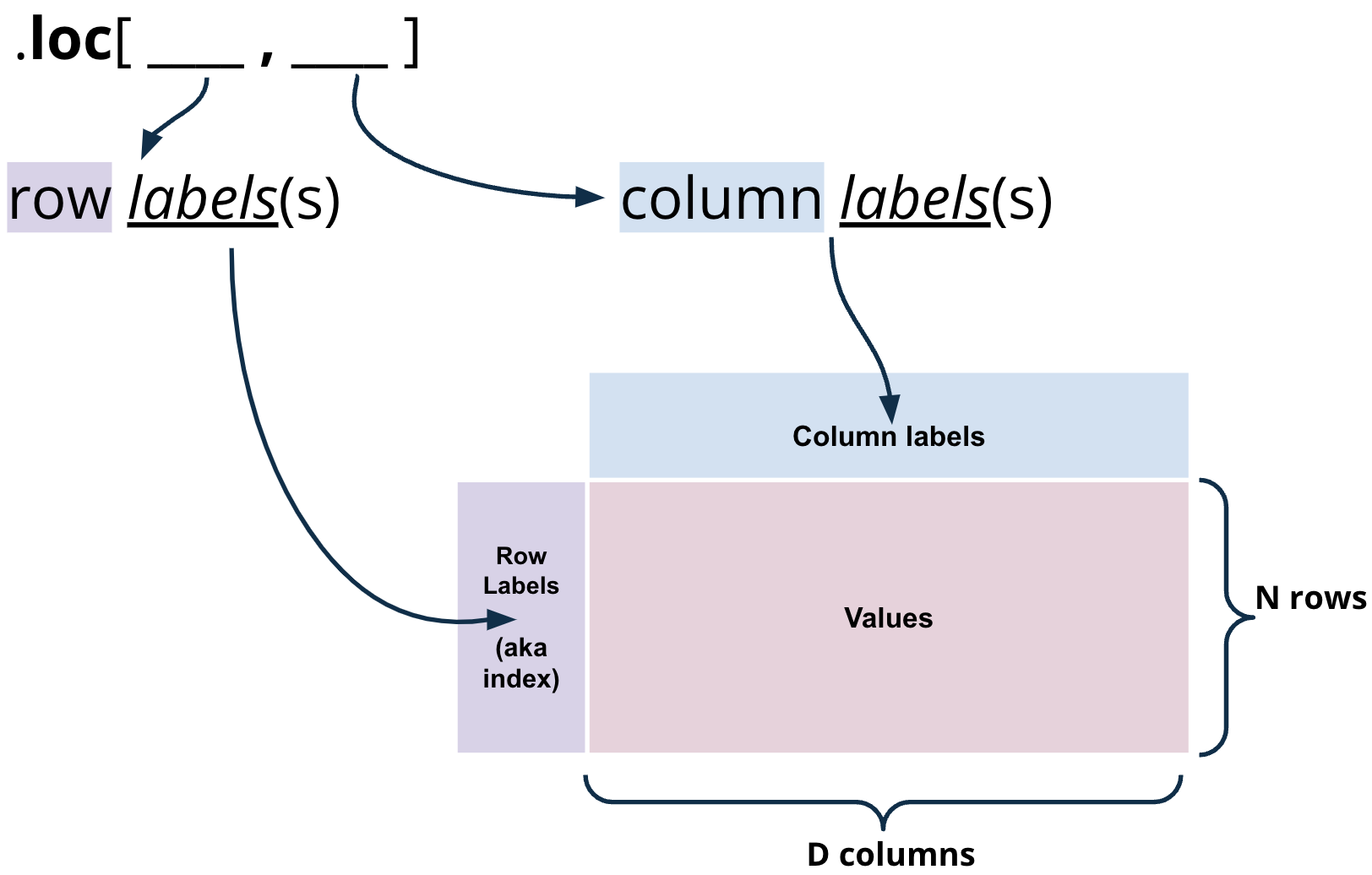
To grab data with .loc, we must specify the row and column label(s) where the data exists. The row labels are the first argument to the .loc function; the column labels are the second. For example, we can select the the row labeled 0 and the column labeled Candidate from the elections DataFrame.
To select multiple rows and columns, we can use Python slice notation. Here, we select the rows from labels 0 to 3 and the columns from labels "Year" to "Popular vote".
elections.loc[0:3, 'Year':'Popular vote']Suppose that instead, we wanted every column value for the first four rows in the elections DataFrame. The shorthand : is useful for this.
elections.loc[0:3, :]There are a couple of things we should note. Firstly, unlike conventional Python, Pandas allows us to slice string values (in our example, the column labels). Secondly, slicing with .loc is inclusive. Notice how our resulting DataFrame includes every row and column between and including the slice labels we specified.
Equivalently, we can use a list to obtain multiple rows and columns in our elections DataFrame. elections.loc[[0, 1, 2, 3], [‘Year’, ‘Candidate’, ‘Party’, ‘Popular vote’]]
Lastly, we can interchange list and slicing notation. elections.loc[[0, 1, 2, 3], :]
.iloc[row_indices, col_indices]
The .iloc[] method is used to access a group of rows and columns by integer position.
Caution
If you find yourself needing to use .iloc then stop and think if you are about to implement a loop. If so, there is probably a better way to do it.
Slicing with .iloc works similarily to .loc, however, .iloc uses the index positions of rows and columns rather the labels (think to yourself: loc uses labels; iloc uses indices). The arguments to the .iloc function also behave similarly -– single values, lists, indices, and any combination of these are permitted.
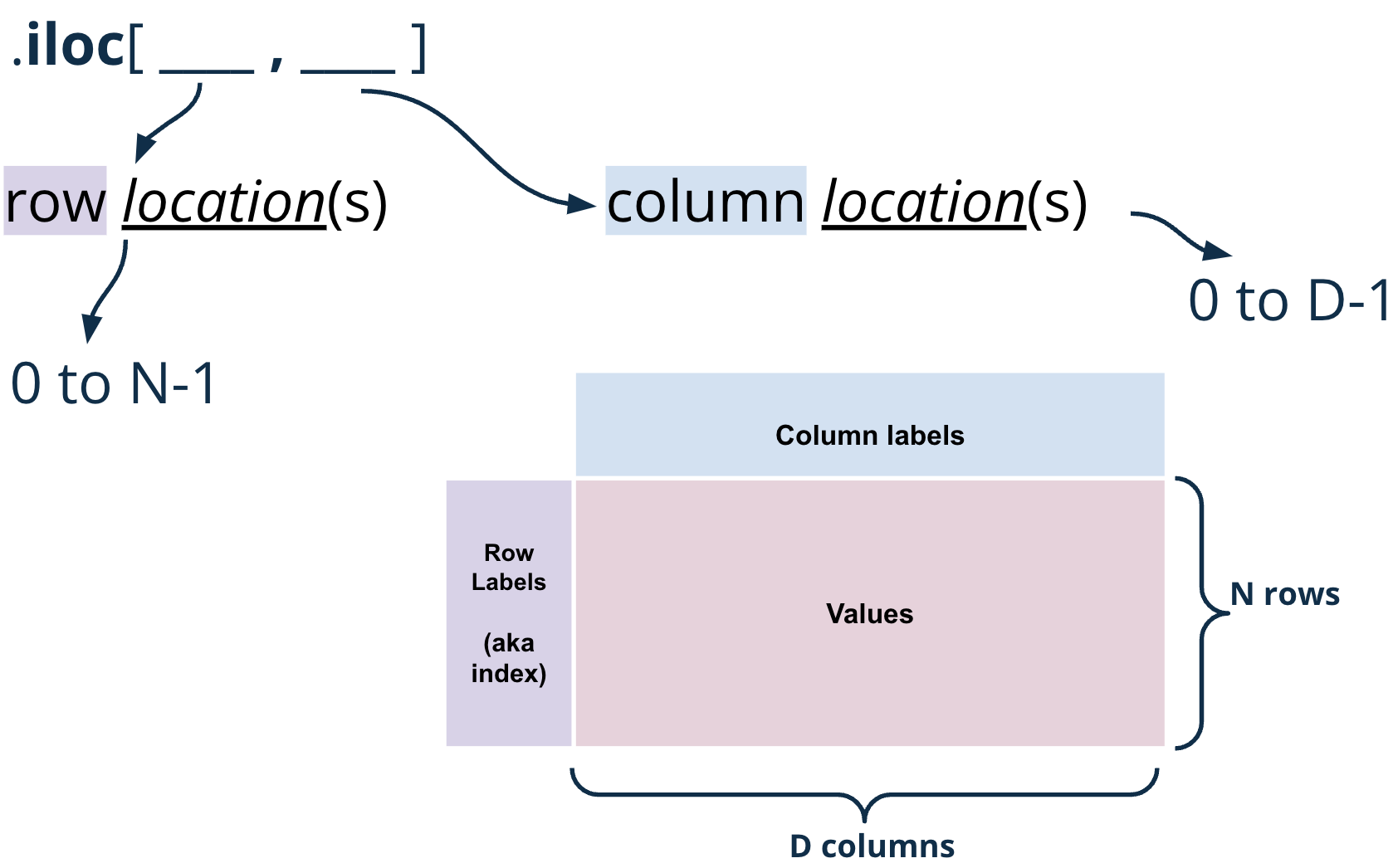
Let’s begin reproducing our results from above. We’ll begin by selecting for the first presidential candidate in our elections DataFrame:
# elections.loc[0, "Candidate"] - Previous approach
elections.iloc[0, 1]Notice how the first argument to both .loc and .iloc are the same. This is because the row with a label of 0 is conveniently in the 0th index (equivalently, the first position) of the elections DataFrame. Generally, this is true of any DataFrame where the row labels are incremented in ascending order from 0.
However, when we select the first four rows and columns using .iloc, we notice something.
# elections.loc[0:3, 'Year':'Popular vote'] - Previous approach
elections.iloc[0:4, 0:4]Slicing is no longer inclusive in .iloc -– it’s exclusive. In other words, the right-end of a slice is not included when using .iloc. This is one of the subtleties of pandas syntax; you will get used to it with practice.
#elections.loc[[0, 1, 2, 3], ['Year', 'Candidate', 'Party', 'Popular vote']] - Previous Approach
elections.iloc[[0, 1, 2, 3], [0, 1, 2, 3]]This discussion begs the question: when should we use .loc vs .iloc? In most cases, .loc is generally safer to use. You can imagine .iloc may return incorrect values when applied to a dataset where the ordering of data can change.
Dropping rows and columns
To drop rows and columns in a DataFrame, we can use the drop() method.
For example, to drop the first row from the election DataFrame, we can use the following code:
elections.head()| Year | Candidate | Party | Popular vote | Result | % | |
|---|---|---|---|---|---|---|
| 0 | 1824 | Andrew Jackson | Democratic-Republican | 151271 | loss | 57.210122 |
| 1 | 1824 | John Quincy Adams | Democratic-Republican | 113142 | win | 42.789878 |
| 2 | 1828 | Andrew Jackson | Democratic | 642806 | win | 56.203927 |
| 3 | 1828 | John Quincy Adams | National Republican | 500897 | loss | 43.796073 |
| 4 | 1832 | Andrew Jackson | Democratic | 702735 | win | 54.574789 |
elections.drop(columns=['Popular vote'])| Year | Candidate | Party | Result | % | |
|---|---|---|---|---|---|
| 0 | 1824 | Andrew Jackson | Democratic-Republican | loss | 57.210122 |
| 1 | 1824 | John Quincy Adams | Democratic-Republican | win | 42.789878 |
| 2 | 1828 | Andrew Jackson | Democratic | win | 56.203927 |
| 3 | 1828 | John Quincy Adams | National Republican | loss | 43.796073 |
| 4 | 1832 | Andrew Jackson | Democratic | win | 54.574789 |
| ... | ... | ... | ... | ... | ... |
| 177 | 2016 | Jill Stein | Green | loss | 1.073699 |
| 178 | 2020 | Joseph Biden | Democratic | win | 51.311515 |
| 179 | 2020 | Donald Trump | Republican | loss | 46.858542 |
| 180 | 2020 | Jo Jorgensen | Libertarian | loss | 1.177979 |
| 181 | 2020 | Howard Hawkins | Green | loss | 0.255731 |
182 rows × 5 columns
# Drop the first row
elections.drop(index=0)
# Drop the first two rows
elections.drop(index=[0, 1])| Year | Candidate | Party | Popular vote | Result | % | |
|---|---|---|---|---|---|---|
| 2 | 1828 | Andrew Jackson | Democratic | 642806 | win | 56.203927 |
| 3 | 1828 | John Quincy Adams | National Republican | 500897 | loss | 43.796073 |
| 4 | 1832 | Andrew Jackson | Democratic | 702735 | win | 54.574789 |
| 5 | 1832 | Henry Clay | National Republican | 484205 | loss | 37.603628 |
| 6 | 1832 | William Wirt | Anti-Masonic | 100715 | loss | 7.821583 |
| ... | ... | ... | ... | ... | ... | ... |
| 177 | 2016 | Jill Stein | Green | 1457226 | loss | 1.073699 |
| 178 | 2020 | Joseph Biden | Democratic | 81268924 | win | 51.311515 |
| 179 | 2020 | Donald Trump | Republican | 74216154 | loss | 46.858542 |
| 180 | 2020 | Jo Jorgensen | Libertarian | 1865724 | loss | 1.177979 |
| 181 | 2020 | Howard Hawkins | Green | 405035 | loss | 0.255731 |
180 rows × 6 columns