import pandas as pd
elections = pd.read_csv('../data/elections.csv')
def extract_first_name(name):
# name is of type string e.g. "Andrew Jackson"
space_separated_substrings = name.split(" ")
first_name = space_separated_substrings[0]
return first_name
candidate_column = elections['Candidate']
elections['first_name'] = candidate_column.apply(extract_first_name)Applying custom functions
Applying a custom user-defined function to a DataFrame is a common operation in pandas.
It allows us to implement custom transformations on the data that are not available in the standard library.
The apply method can be used in the following way:
- on each value (scalar) of a pd.Series:
df[col].apply(func) - on each column of a pd.DataFrame:
df.apply(func, axis=0) - on each row of a pd.DataFrame:
df.apply(func, axis=1)
Each of these operations is distinct in terms of the shape of the output and the arguments that the function being applied takes.
| code | x |
argument to the function f |
Expected return type of f |
y |
|
|---|---|---|---|---|---|
1 |
x=df[col]y=x.apply(f) |
pd.Series of length \(n\) |
scalar |
scalar |
pd.Series of length \(n\) |
| 2 | y=x.apply(f,axis=0) |
pd.DataFrame of shape \((n, d)\) |
pd.Series of length \(n\) | scalar | pd.Series of length \(d\) |
| 3 | y=x.apply(f,axis=1) |
pd.DataFrame of shape \((n, d)\) |
pd.Series of length \(d\) | scalar | pd.Series of length \(n\) |
1. Applying a function to each value of a pd.Series
In our elections dataset, we have a column Candidate that contains the name of the candidate that each vote was cast for.
Let’s say we wanted to extract the first name of each candidate. We can use the apply method to apply a custom function that extracts the first name from a string.
Note that the function extract_first_name takes a scalar input (a string): Candidate and returns a scalar output (a string): first_name.
Our function extract_first_name is called on each value of the Candidate column so \(n\) times where \(n\) is the number of rows in the DataFrame.

The function extract_first_name returns back a scalar value for each input value. All together, we get a pd.Series of length \(n\) where each value is the first name of the candidate.
2. Applying a function to each column of a pd.DataFrame (axis=0)
data.apply(f, axis=0) applies the function f to each column of the DataFrame data.
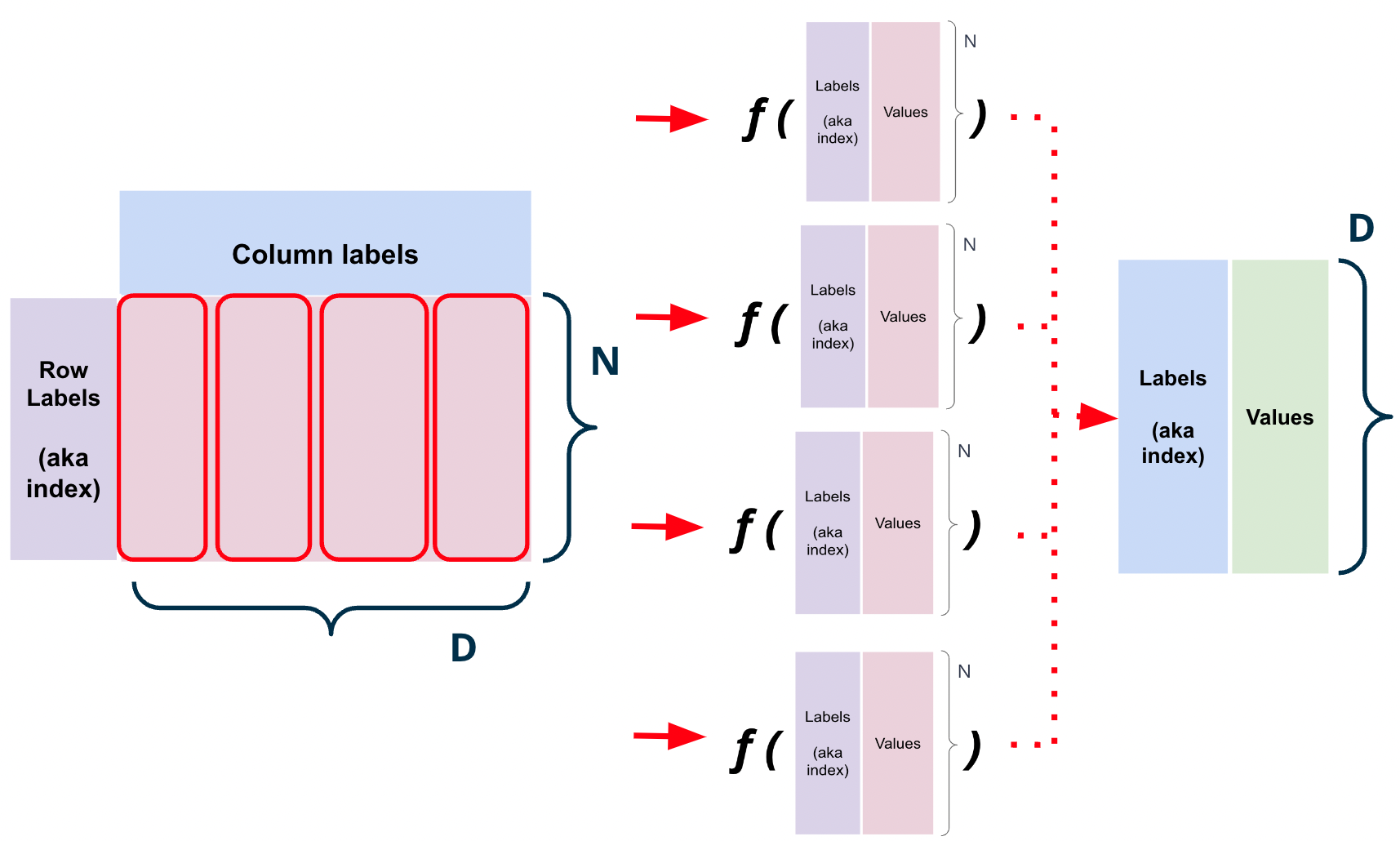
For example, if we wanted to find the number of unique values in each column of a DataFrame data, we could use the following code:
def count_unique(col):
return len(set(col))
elections.apply(count_unique, axis="index") # function is passed an individual column3. Applying a function to each row of a pd.DataFrame (axis=1)
data.apply(f, axis=1) applies the function f to each row of the DataFrame data.
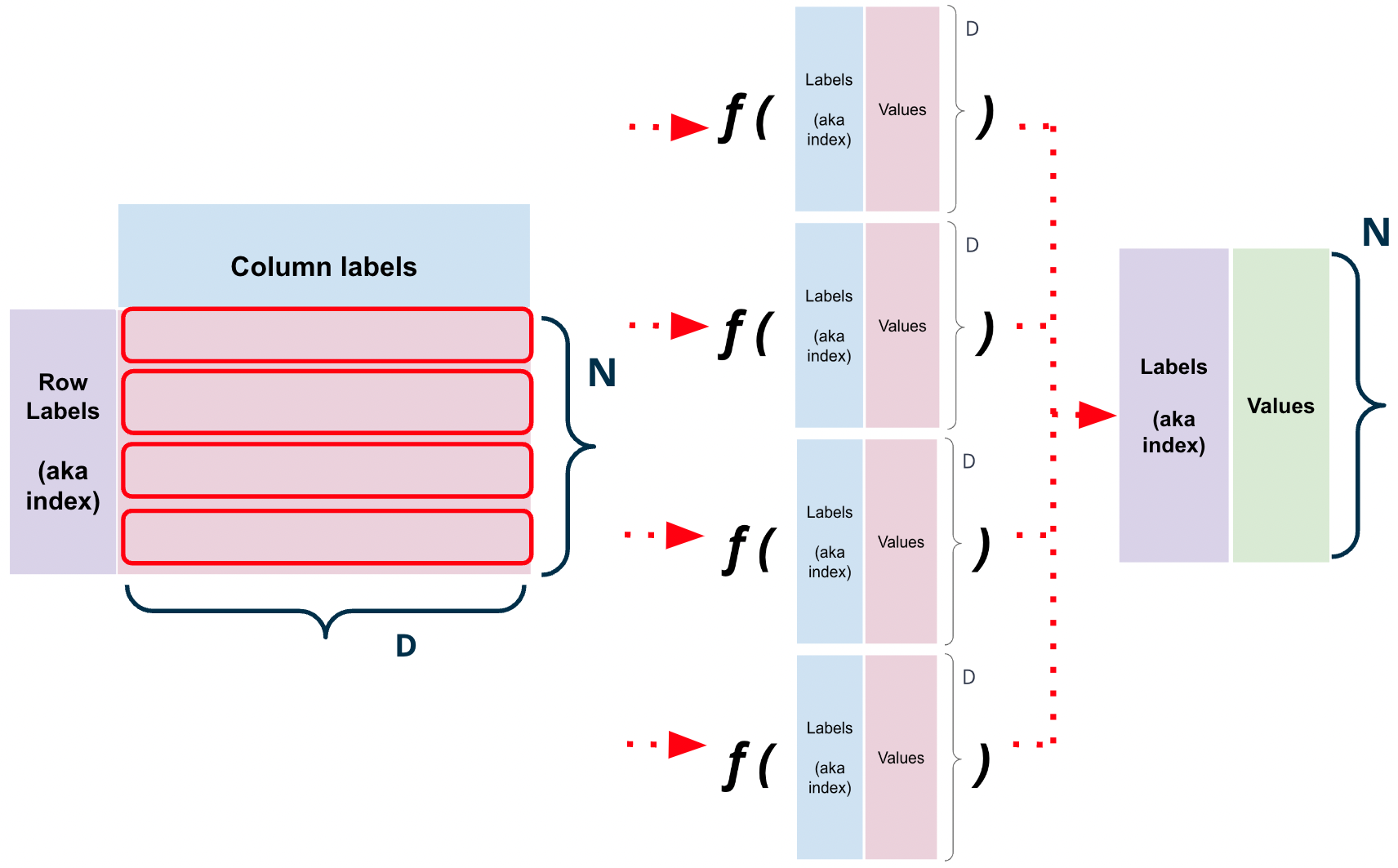
For instance, let’s say we wanted to count the total number of voters in an election.
We can use .apply to answer that question using the following formula:
\[ \text{total} \times \frac{\%}{100} = \text{Popular vote} \]
def compute_total(row):
return int(row['Popular vote']*100/row['%'])
elections.apply(compute_total, axis=1)0 264413
1 264412
2 1143702
3 1143703
4 1287655
...
177 135720167
178 158383403
179 158383403
180 158383401
181 158383402
Length: 182, dtype: int64Anonymous functions
Anonymous functions are functions that are defined without a name.
In Python, we use the lambda keyword to create anonymous functions.
The syntax of a lambda function is:
lambda arguments: expressionLambda functions can have any number of arguments but only one expression, which is evaluated and returned, without using the return keyword.
They are useful when we need a simple function that we will only use once.
For example, let’s say we wanted to add 1 to each element in a DataFrame. We could use an anonymous function to do this:
double = lambda x: x * 2
double(5) # returns 10
multiplyby2 = double
multiplyby2(5) # returns 10Note that in the above example, double is not a function name per se. It is a variable that refers to the anonymous function lambda x: x * 2.
Anonymous functions with .apply
We can use anonymous functions with .apply to apply a function to each column or row of a DataFrame.
For example, let’s say we wanted to find the number of unique values in each column of a DataFrame data. We could use the following code:
data.apply(lambda x: x.nunique())Let’s say we wanted to count the total number of voters in an election. We can use .apply to answer that question using the following formula:
data['Popular vote'] = data.apply(lambda row: row['total'] * row['%'] / 100, axis=1)