Vectors have two common geometric interpretations:
Vectors as Points in Feature Space: In this interpretation, we consider vectors as points in a space with a fixed reference point called the origin.
Vectors as Displacement: In this interpretation, we consider vectors as displacements between points in space.
1. Vectors as Points in Feature Space
Given a vector, the first interpretation that we should give it is as a point in space.
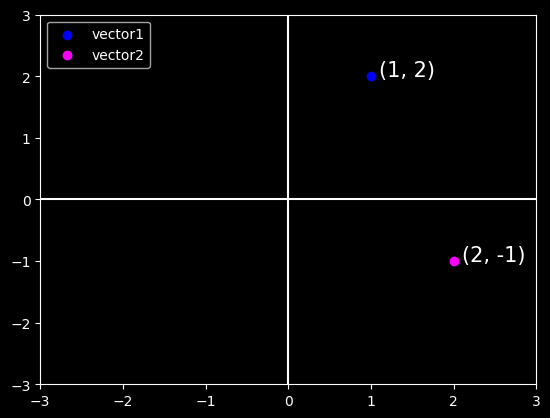
In two or three dimensions, we can visualize these points by using the components of the vectors to define the location of the points in space compared to a fixed reference called the origin. This can be seen in the figure below.
This geometric point of view allows us to consider the problem on a more abstract level. No longer faced with some insurmountable seeming problem like classifying pictures as either cats or dogs, we can start considering tasks abstractly as collections of points in space and picturing the task as discovering how to separate two distinct clusters of points.
import pandas as pd from matplotlib import pyplot as pltplt.style.use('dark_background')plt.xlim(-3, 3)plt.ylim(-3, 3)vector1 = [1, 2]vector2 = [2, -1]displacement =0.1# Plotting vector 1plt.scatter(x=vector1[0], y=vector1[1], color='blue');plt.text(x=vector1[0]+displacement, y=vector1[1], \ s=f"(%s, %s)"% (vector1[0], vector1[1]), size=15);# Plotting vector 2plt.scatter(x=vector2[0], y=vector2[1], color='magenta');plt.text(x=vector2[0]+displacement, y=vector2[1], \ s=f"(%s, %s)"% (vector2[0], vector2[1]), size=15);# Plotting the x and y axesplt.axhline(0, color='white');plt.axvline(0, color='white');# Plotting the legendplt.legend(['vector1', 'vector2'], loc='upper left');
2. Vectors as directions in feature space
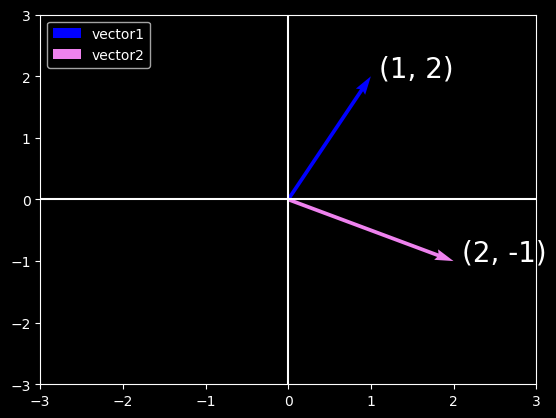
In parallel, there is a second point of view that people often take of vectors: as directions in space. Not only can we think of the vector \(\textbf{v} = [3, 2]^{T}\) as the location \(3\) units to the right and \(2\) units up from the origin, we can also think of it as the direction itself to take \(3\) steps to the right and \(2\) steps up. In this way, we consider all the vectors in figure below the same.
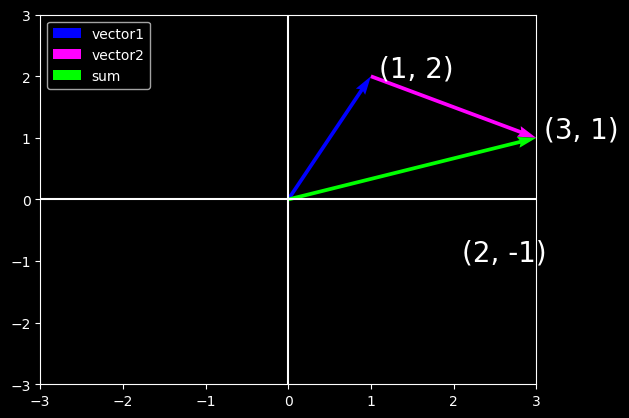
One of the benefits of this shift is that we can make visual sense of the act of vector addition. In particular, we follow the directions given by one vector, and then follow the directions given by the other, as seen below:
Vector subtraction has a similar interpretation. By considering the identity that \(\mathbf{u} = \mathbf{v} + (\mathbf{u} - \mathbf{v})\), we see that the vector \(\mathbf{u} - \mathbf{v}\) is the direction that takes us from the point \(\mathbf{v}\) to the point \(\mathbf{u}\).
Some of the most useful operators in linear algebra are norms. A norm is a function \(\| \cdot \|\) that maps a vector to a scalar.
Informally, the norm of a vector tells us magnitude or length of the vector.
For instance, the \(l_2\) norm measures the euclidean length of a vector. That is, \(l_2\) norm measures the euclidean distance of a vector from the origin \((0, 0)\).
x = pd.Series(vector1)l2_norm = (x**2).sum()**(1/2)l2_norm
2.23606797749979
The \(l_1\) norm is also common and the associated measure is called the Manhattan distance. By definition, the \(l_1\) norm sums the absolute values of a vector’s elements:
One of the most fundamental operations in linear algebra (and all of data science and machine learning) is the dot product.
Given two vectors \(\textbf{x}, \textbf{y} \in \mathbb{R}^d\), their dot product\(\textbf{x}^{\top} \textbf{y}\) (also known as inner product\(\langle \textbf{x}, \textbf{y} \rangle\)) is a sum over the products of the elements at the same position:
Equivalently, we can calculate the dot product of two vectors by performing an elementwise multiplication followed by a sum:
sum(x * y)
32
Dot products are useful in a wide range of contexts. For example, given some set of values, denoted by a vector $ ^{n} $ , and a set of weights, denoted by \(\mathbf{x} \in \mathbb{R}^{n}\), the weighted sum of the values in \(\mathbf{x}\) according to the weights \(\mathbf{w}\) could be expressed as the dot product \(\mathbf{x}^\top \mathbf{w}\). When the weights are nonnegative and sum to \(1\), i.e., \((\sum_{i=1}^n w_i = 1)\), the dot product expresses a weighted average. After normalizing two vectors to have unit length, the dot products express the cosine of the angle between them. Later in this section, we will formally introduce this notion of length.
Dot Products and Angles
If we take two column vectors \(\mathbf{u}\) and \(\mathbf{v}\), we can form their dot product by computing:
The vector \(\mathbf{v}\) is length \(r\) and runs parallel to the \(x\)-axis, and the vector \(\mathbf{w}\) is of length \(s\) and at angle \(\theta\) with the \(x\)-axis.
If we compute the dot product of these two vectors, we see that
We will not use it right now, but it is useful to know that we will refer to vectors for which the angle is \(\pi/2\)(or equivalently \(90^{\circ}\)) as being orthogonal.
By examining the equation above, we see that this happens when \(\theta = \pi/2\), which is the same thing as \(cos(\theta) = 0\).
The only way this can happen is if the dot product itself is zero, and two vectors are orthogonal if and only if \(\mathbf{v}\cdot\mathbf{w} = 0\).
This will prove to be a helpful formula when understanding objects geometrically.
It is reasonable to ask: why is computing the angle useful? Consider the problem of classifying text data. We might want the topic or sentiment in the text to not change if we write twice as long of document that says the same thing.
For some encoding (such as counting the number of occurrences of words in some vocabulary), this corresponds to a doubling of the vector encoding the document, so again we can use the angle.
v = pd.Series([0, 2])w = pd.Series([2, 0])v.dot(w)
0
from math import acosdef l2_norm(vec):return (vec**2).sum()**(1/2)v = pd.Series([0, 2])w = pd.Series([2, 0])v.dot(w) / (l2_norm(v) * l2_norm(w))
0.0
from math import acos, pitheta = acos(v.dot(w) / (l2_norm(v) * l2_norm(w)))theta == pi /2
True
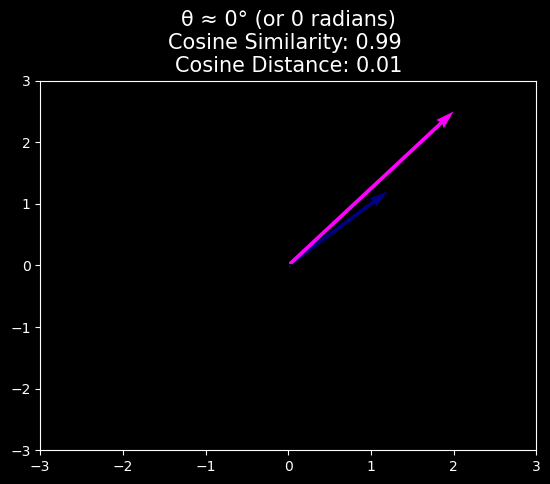
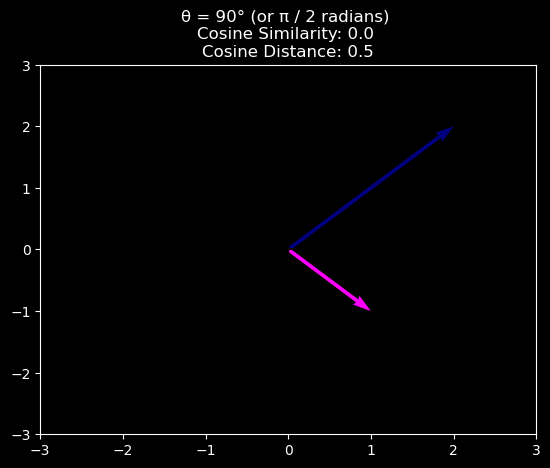
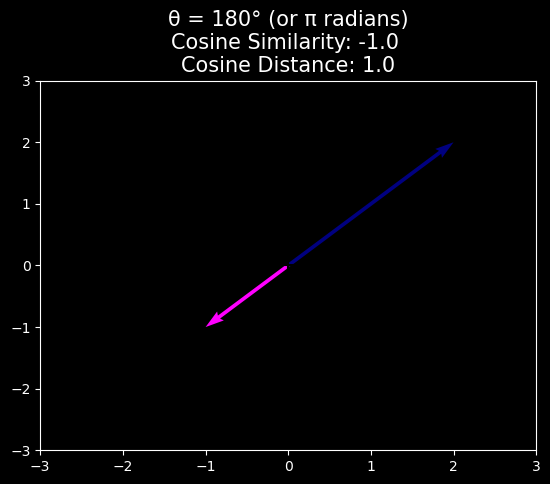
Cosine Similarity/Distance
In ML contexts where the angle is employed to measure the closeness of two vectors, practitioners adopt the term cosine similarity to refer to the portion
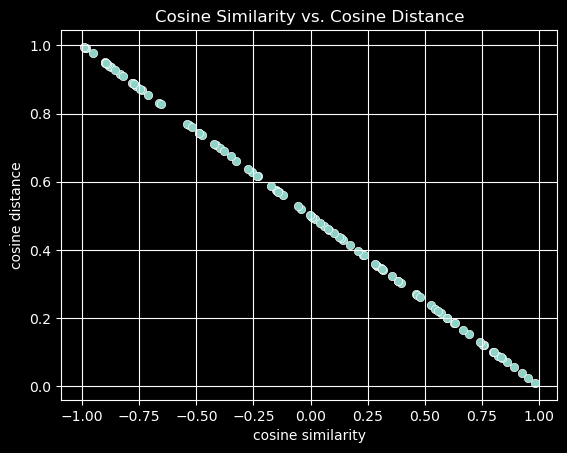
The cosine takes a maximum value of \(1\) when the two vectors point in the same direction, a minimum value of \(-1\) when they point in opposite directions, and a value of \(0\) when the two vectors are orthogonal.
Note that cosine similarity can be converted to cosine distance by subtracting it from \(1\) and dividing by 2.
where \(\text{Cosine Similarity} = \frac{\mathbf{v}\cdot\mathbf{w}}{\|\mathbf{v}\|\|\mathbf{w}\|}\)
Cosine distance is a very useful alternative to Euclidean distance for data where the absolute magnitude of the features is not particularly meaningful, which is a very common scenario in practice.
from random import uniformimport pandas as pdimport seaborn as snsdf = pd.DataFrame()df['cosine similarity'] = pd.Series([uniform(-1, 1) for i inrange(100)])df['cosine distance'] = (1- df['cosine similarity'])/2ax = sns.scatterplot(data=df, x='cosine similarity', y='cosine distance');ax.set(title='Cosine Similarity vs. Cosine Distance')plt.grid()
Note that cosine similarity can be negative, which means that the angle is greater than \(90^{\circ}\), i.e., the vectors point in opposite directions.
We denote matrices by bold capital letters (e.g., \(X\), \(Y\), and \(Z\)), and represent them in code by pd.DataFrame. The expression \(\mathbf{A} \in \mathbb{R}^{m \times n}\) indicates that a matrix \(\textbf{A}\) contains \(m \times n\) real-valued scalars, arranged as \(m\) rows and \(n\) columns. When \(m = n\), we say that a matrix is square. Visually, we can illustrate any matrix as a table. To refer to an individual element, we subscript both the row and column indices, e.g., \(a_{ij}\) is the value that belongs to \(\mathbf{A}\)’s \(i^{th}\) row and \(j^{th}\) column:
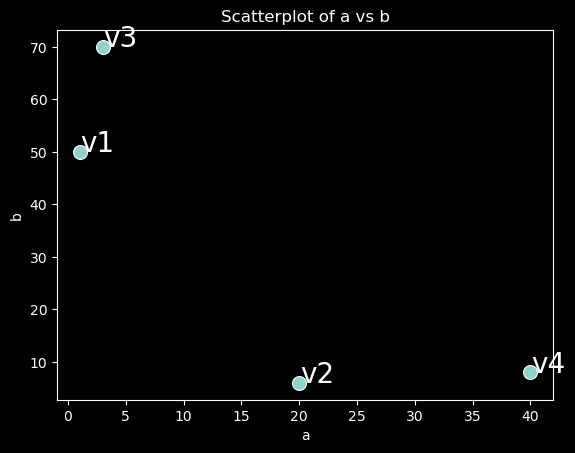
An (n, d) matrix can be interpreted as a collection of n vectors in d-dimensional space.
import seaborn as snsfrom matplotlib import pyplot as pltplt.style.use('dark_background')ax = sns.scatterplot(x='a', y='b', data=df, s=100);ax.set(title='Scatterplot of a vs b', xlabel='a', ylabel='b');def annotate(row): plt.text(x=row['a']+0.05, y=row['b'], s=row.name, size=20);df.apply(annotate, axis=1);
Transpose
Sometimes we want to flip the axes. When we exchange a matrix’s rows and columns, the result is called its transpose. Formally, we signify a matrix’s \(\textbf{A}\) transpose by \(\mathbf{A}^\top\) and if \(\mathbf{B} = \mathbf{A}^\top\), then \(b_{ij} = a_{ij}\) for all \(i\) and \(j\). Thus, the transpose of an \(m \times n\) matrix is an \(n \times m\) matrix:
In pandas, you can transpose a DataFrame with the .T attribute:
df.T
v1
v2
v3
v4
a
1
20
3
40
b
50
6
70
8
Note that columns of original dataframe df are the same as index of df.T
df.columns == df.T.index
array([ True, True])
df.T
v1
v2
v3
v4
a
1
20
3
40
b
50
6
70
8
Matrix-Vector Products
Now that we know how to calculate dot products, we can begin to understand the product between an \(m \times n\) matrix and an \(n\)-dimensional vector \(\mathbf{x}\).
To start off, we visualize our matrix in terms of its row vectors
where each \(\mathbf{a}^\top_{i} \in \mathbb{R}^n\) is a row vector representing the \(i^\textrm{th}\) row of the matrix \(\mathbf{A}\).
The matrix–vector product \(\mathbf{A}\mathbf{x}\) is simply a column vector of length \(m\) , whose \(i^{th}\) element is the dot product \(\mathbf{a}^\top_i \mathbf{x}\)
We can think of multiplication with a matrix \(\mathbf{A}\in \mathbb{R}^{m \times n}\) as a transformation that projects vectors from \(\mathbb{R}^{n}\) to \(\mathbb{R}^{m}\).
These transformations are remarkably useful. For example, we can represent rotations as multiplications by certain square matrices. Matrix–vector products also describe the key calculation involved in computing the outputs of each layer in a neural network given the outputs from the previous layer.
Finding similar vectors
Note that, given a vector \(\mathbf{v}\), vector-matrix products can also be used to compute the similarity of \(\mathbf{v}\) and each row \(\mathbf{a}^\top_i\) of matrix \(\mathbf{A}\). This is because the matrix-vector product \(\mathbf{A}\mathbf{v}\) will contain the dot products of \(\mathbf{v}\) and each row in \(\mathbf{A}\).
There is one thing to be careful about: recall that the formula for cosine similarity is:
The dot product (numerator, on the right hand side) is equal to the cosine of the angle between the two vectors when the vectors are normalized (i.e. each divided by their norms).
The example below shows how to compute the cosine similarity between a vector \(\mathbf{v}\) and each row of matrix \(\mathbf{A}\).
import pandas as pddata = pd.read_csv('https://raw.githubusercontent.com/fahadsultan/csc272/main/data/chat_dataset.csv')
# creating bow representationvocab = (' '.join(data['message'].values)).lower().split()bow = pd.DataFrame(columns=vocab)for word in vocab: bow[word] = data['message'].apply(lambda msg: msg.count(word))
# l2 norm of a vectordef l2_norm(vec):return (sum(vec**2))**(1/2)# bow where each row is a unit vectors i.e. ||row|| = 1bow_unit = bow.apply(lambda row: row/l2_norm(row), axis=1)
# random message : I don't have an opinion on thismsg = bow_unit.iloc[20] # cosine similarity of first message with all other messagesmsg_sim = bow_unit.dot(msg.T)msg_sim.index = data['message']msg_sim.sort_values(ascending=False)
message
I don't have an opinion on this 1.000000
I don't really have an opinion on this 0.984003
I have no strong opinion about this 0.971575
I have no strong opinions about this 0.971226
I have no strong opinion on this 0.969768
...
I'm not sure what to do 😕 0.204587
I'm not sure what to do next 🤷♂️ 0.201635
I'm not sure what to do next 🤔 0.200593
The food was not good 0.200295
The food was not very good 0.197220
Length: 584, dtype: float64
Matrix-Matrix Multiplication
Once you have gotten the hang of dot products and matrix–vector products, then matrix–matrix multiplication should be straightforward.
Say that we have two matrices \(\mathbf{A} \in \mathbb{R}^{n \times k}\) and \(\mathbf{B} \in \mathbb{R}^{k \times m}\):
Let \(\mathbf{a}^\top_{i} \in \mathbb{R}^k\) denote the row vector representing the \(i^\textrm{th}\) row of the matrix \(\mathbf{A}\) and let \(\mathbf{b}_{j} \in \mathbb{R}^k\) denote the column vector from the \(j^\textrm{th}\) column of the matrix \(\mathbf{B}\) :
To form the matrix product \(\mathbf{C} \in \mathbb{R}^{n \times m}\) , we simply compute each element \(c_{ij}\) as the dot product between the \(i^{\textrm{th}}\) row of \(\mathbf{A}\) and the \(i^{\textrm{th}}\) column of \(\mathbf{B}\) , i.e., \(\mathbf{a}^\top_i \mathbf{b}_j\) :
We can think of the matrix–matrix multiplication \(\mathbf{AB}\) as performing \(m\) matrix–vector products or \(m \times n\) dot products and stitching the results together to form an \(m \times n\) matrix. In the following snippet, we perform matrix multiplication on A and B. Here, A is a matrix with two rows and three columns, and B is a matrix with three rows and four columns. After multiplication, we obtain a matrix with two rows and four columns.
Computing similarity / distance matrix
Note that, given two matrices \(\mathbf{A}\) and \(\mathbf{B}\), matrix-matrix products can also be used to compute the similarity between each row \(\mathbf{a}^\top_i\) of matrix \(\mathbf{A}\) and each row \(\mathbf{b}^\top_j\) of matrix \(\mathbf{B}\). This is because the matrix-matrix product \(\mathbf{A}\mathbf{B}\) will contain the dot products of each pair of rows in \(\mathbf{A}\) and \(\mathbf{B}\).
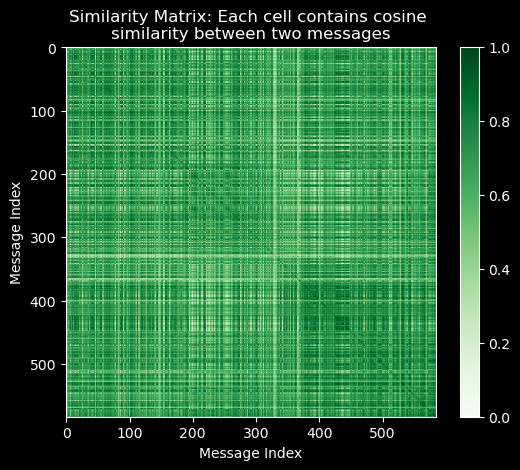
from matplotlib import pyplot as pltplt.imshow(similarity_matrix, cmap='Greens')plt.colorbar();plt.title("Similarity Matrix: Each cell contains cosine \nsimilarity between two messages");plt.xlabel("Message Index");plt.ylabel("Message Index");
Note how 1. the similarity matrix is symmetric, i.e. \(sim_{ij} = sim_{ji}\) and 2. the diagonal elements are all 1, i.e. \(sim_{ii} = 1\).
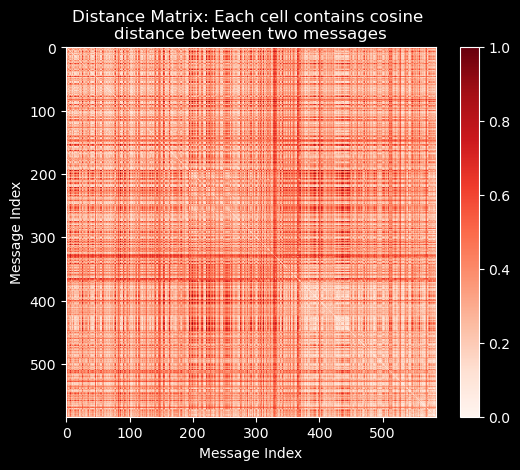
distance_matrix =1- bow_unit.dot(bow_unit.T)from matplotlib import pyplot as pltplt.imshow(distance_matrix, cmap='Reds')plt.colorbar();plt.title("Distance Matrix: Each cell contains cosine \ndistance between two messages");plt.xlabel("Message Index");plt.ylabel("Message Index");
Nearest Neighbor
Nearest Neighbor is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions). It is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until function evaluation.
Training stage: The algorithm stores all the training data.
Testing stage: The algorithm compares the test data with the training data and returns the most similar data.
The algorithm is based on the assumption that the data points that are close to each other are similar. The similarity is calculated using a distance function, such as Euclidean distance, Manhattan distance, Minkowski distance, etc.
The algorithm is simple and easy to implement, but it is computationally expensive, especially when the training data is large. It is also sensitive to the curse of dimensionality, which means that the algorithm’s performance deteriorates as the number of dimensions increases.
Pseudocode
The pseudocode for the nearest neighbor algorithm is as follows:
For each test data point:
Calculate the distance between the test data point and all training data points.
Sort the distances in ascending order.
Select the nearest data points.
Determine the class of the nearest data points.
Assign the test data point to the nearest neighbor class.
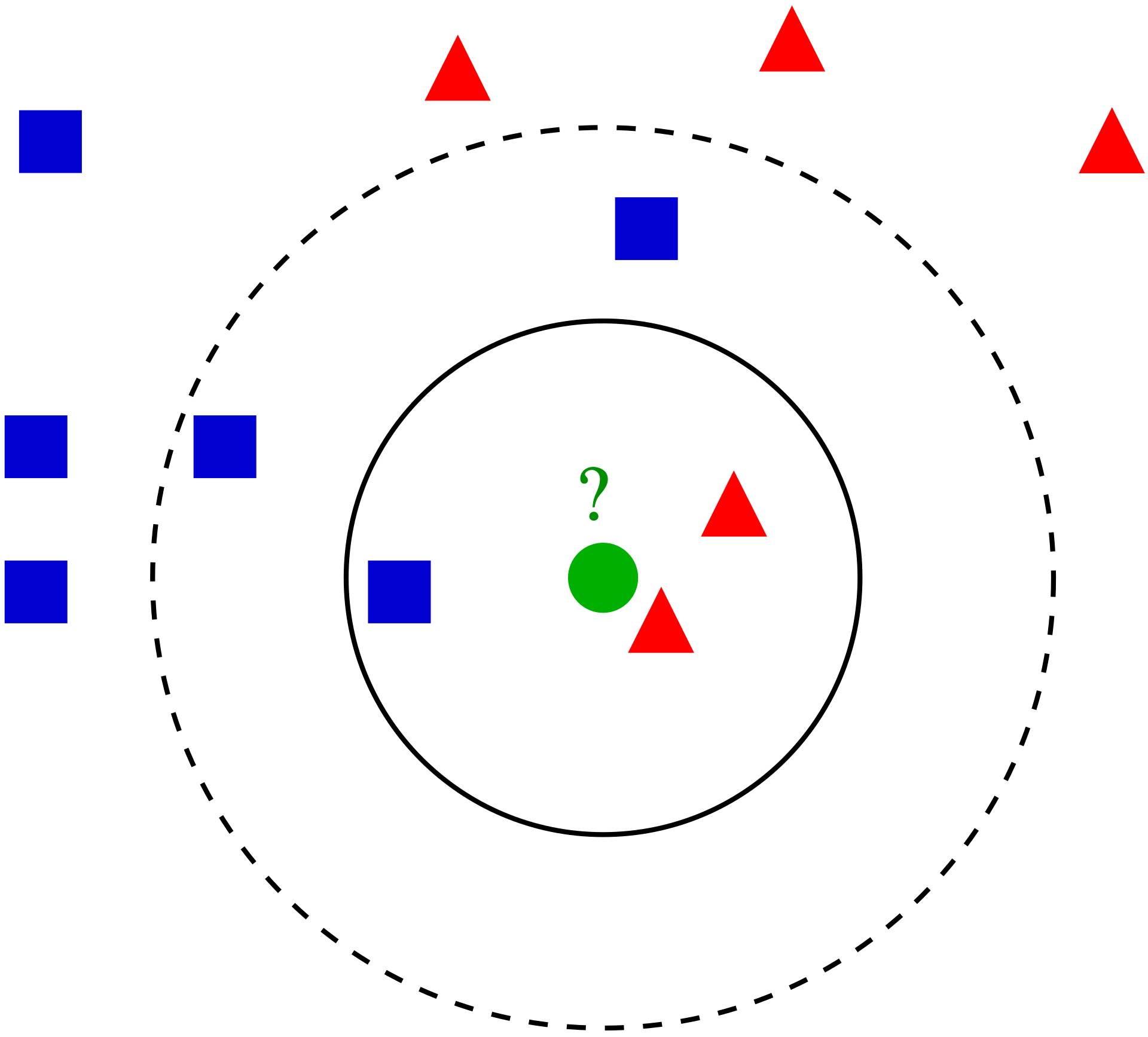
k-NN Algorithm
The k-NN algorithm is an extension of the nearest neighbor algorithm. Instead of returning the most similar data point, the algorithm returns the k most similar data points. The class of the test data is determined by the majority class of the k most similar data points.
For example, in the figure below, the test sample (green dot) should be classified either to blue squares or to red triangles. If k = 3 (solid line circle) it is assigned to the red triangles because there are 2 triangles and only 1 square inside the inner circle. If k = 5 (dashed line circle) it is assigned to the blue squares (3 squares vs. 2 triangles inside the outer circle).
The k-NN algorithm is more robust than the nearest neighbor algorithm, as it reduces the noise in the data. However, it is computationally more expensive, as it requires storing and comparing more data points.
The k-NN algorithm is a simple and effective algorithm for classification and regression tasks. It is widely used in various fields, such as pattern recognition, image processing, and data mining.