8. Supervised Learning#
Supervised learning is similar to how we learn in school.
First, there is a learning or training phase where we learn from lots of examples. Examples are essentially a set of questions and their answers.
The training phase is then followed by a testing phase where we apply our learning to a relatively small set of previously unseen questions.
Finally, there is an evaluation on how well we applied our knowledge to the test questions by comparing our answers to the correct answers.
Most machine learning problems involve predicting a single random variable \(\mathcal{y}\) from one or more random variables \(\mathcal{X}\).
The underlying assumption, when we set out to accomplish this, is that the value of \(\mathcal{y}\) is dependent on the value of \(\mathcal{X}\) and the relationship between the two is governed by some unknown function \(f\) i.e.
\(\mathcal{X}\) is here simply some data that we have as a pandas Dataframe pd.DataFrame whereas \(\mathcal{y}\) here is the target variable, one value for each observation, that we want to predict, as a pandas Series pd.Series.
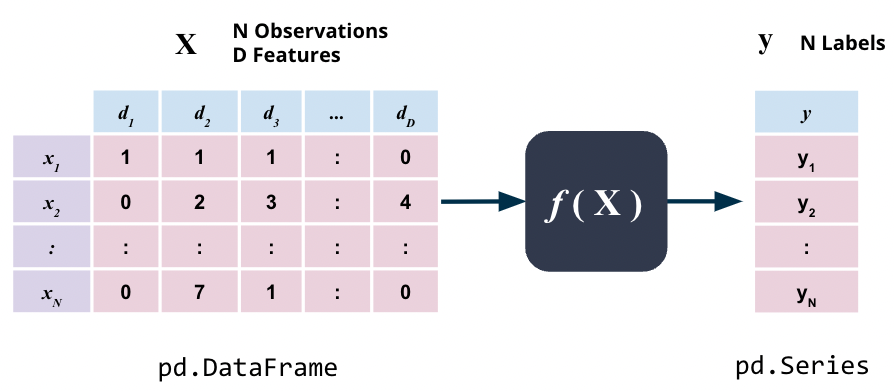
The figure above just depicts the core assumption underlying most machine learning problems.
Assumptions, loosely speaking, are what we formally call models.
Therefore, the basic mathematical model underlying most machine learning problems is that the target variable \(\mathcal{y}\) is a function of the input variables \(\mathcal{X}\) i.e. \(\mathcal{y = f(X)}\).
If this assumption does NOT hold, then there is nothing to learn and we cannot predict \(\mathcal{y}\) from \(\mathcal{X}\). In other words, \(\mathcal{y}\) is independent of \(\mathcal{X}\). For example, if we try to predict the outcome of a coin toss using the time of day, we will fail miserably because the two are independent of each other.
The core problem, distinct from any models or assumptions, here is that the function \(\mathcal{f}\) is unknown to us and we need to ”learn” it from the data.
Such problems fall under the broad category of Supervised Learning.
There are two primary types of supervised learning problems:
Classification - when the target variable \(\mathcal{y}\) is categorical
Regression - when the target variable \(\mathcal{y}\) is continuous
Example Dataset
The code below loads the iris dataset from the sklearn library. This dataset is a classic example of a classification problem.

X is a pandas DataFrame with 4 columns and 150 rows. Each row represents a flower and each column represents a feature of the flower. The features are:
sepal length in cm
sepal width in cm
petal length in cm
petal width in cm
y is a pandas Series with 150 rows. Each row represents the species of the flower. The species are:
Iris Setosa
Iris Versicolour
Iris Virginica
The goal is to predict the species of a flower given its features.
from sklearn.datasets import load_iris
data = load_iris(as_frame=True)
X = data['data']
y = data['target']
print("\n================= X - Features ==================\n")
print(X.sample(5, random_state=42))
print("\n============== y (Classification) ==============\n")
print(y.sample(5, random_state=42))
================= X - Features ==================
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
73 6.1 2.8 4.7 1.2
18 5.7 3.8 1.7 0.3
118 7.7 2.6 6.9 2.3
78 6.0 2.9 4.5 1.5
76 6.8 2.8 4.8 1.4
============== y (Classification) ==============
73 1
18 0
118 2
78 1
76 1
Name: target, dtype: int64
8.1. Train-Test Split#
The first step in supervised learning is to split the data into two sets: a training set and a test set.
The training set is used to train or learn the parameters of the model. The test set is used to evaluate the performance of the learning.
The convention is to use majority of the data for training and the rest for testing. The ratio of training to test data is typically 80:20 or 70:30.
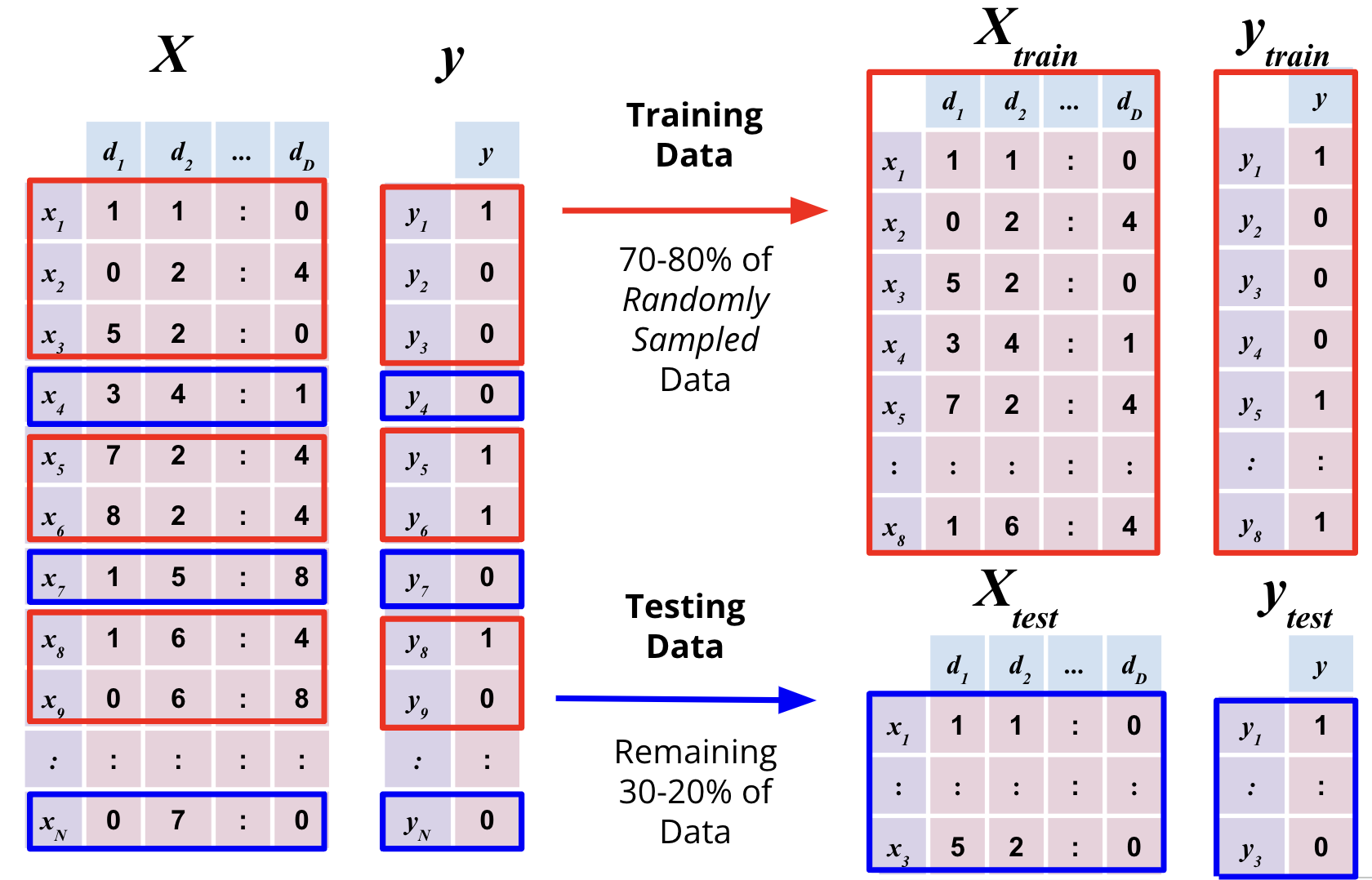
It is extremely important to ensure the following:
The training set and test set are mutually exclusive i.e. no observation in the training set should be in the test set and vice versa.
The train and test sets are representative of the overall data. For example, if the data is sorted by date, then the train set should have observations from all dates and not just the most recent dates.
To ensure this, the train set must be randomly drawn from the data.
This can be implemented by randomly shuffling the data before splitting it into train and test sets or using the built-in .sample method.
8.1.1. Code Example#
The code below uses the train_test_split function from the sklearn library to split the data into train and test sets.
The test_size parameter is set to 0.2 which means that 20% of the data will be used for testing and the remaining 80% will be used for training.
The random_state parameter is set to 42 which means that the random number generator will be initialized to a known state. This ensures that the results are reproducible.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
print("Train set:\n X_train.shape =", X_train.shape, ", y_train.shape =", y_train.shape)
print("Test set: \n X_test.shape =", X_test.shape, ", y_test.shape =", y_test.shape)
Train set:
X_train.shape = (112, 4) , y_train.shape = (112,)
Test set:
X_test.shape = (38, 4) , y_test.shape = (38,)
8.2. Training Phase#
In supervised learning problems, we have a set of observations, each observation consisting of a set of input variables \(\mathcal{X}\) and a target variable \(\mathcal{y}\), and we want to learn a function \(\mathcal{f}\) that maps the input \(\mathcal{X}\) to the output \(\mathcal{y}\).
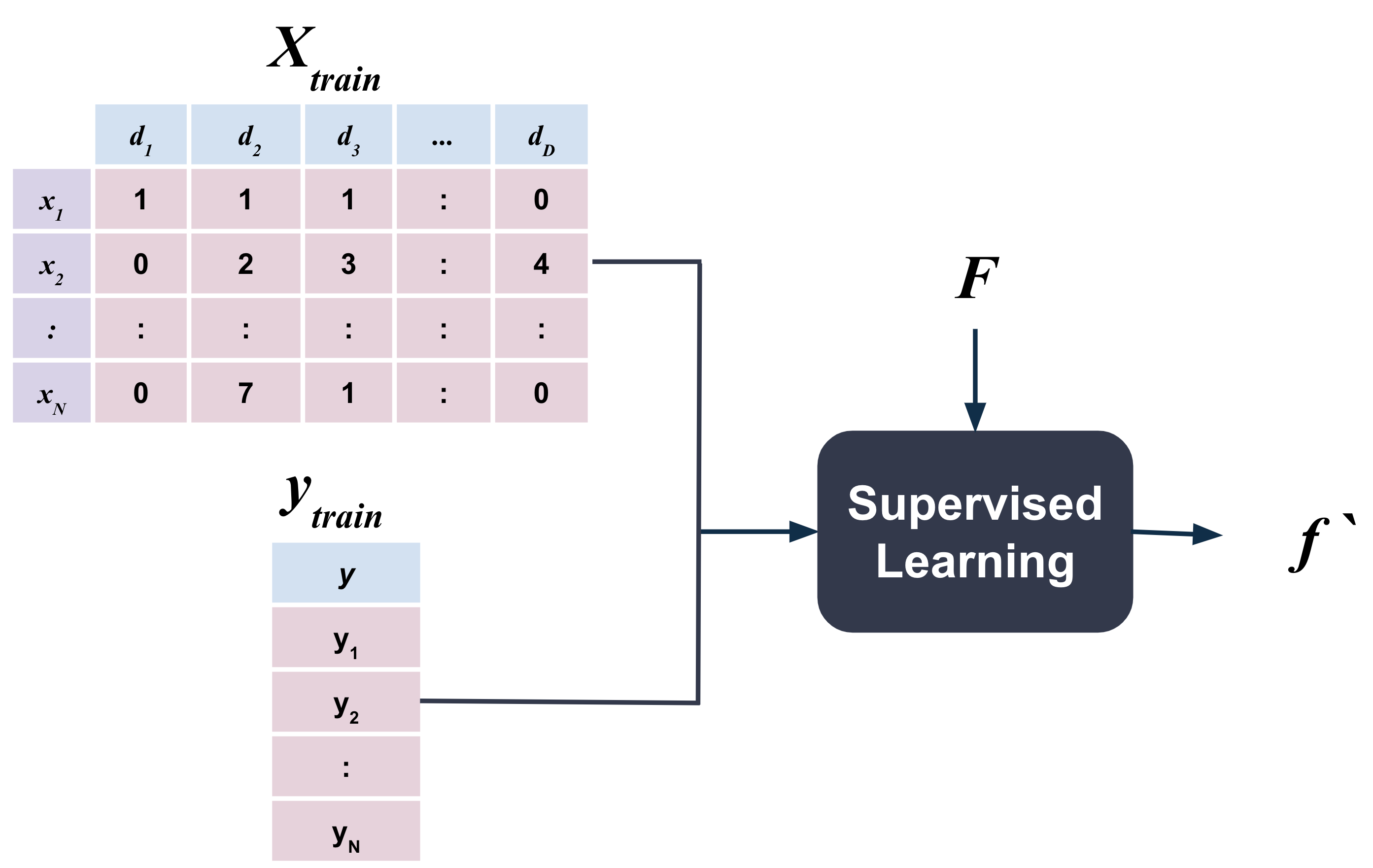
In the figure above, \(F\) is the family of functions that we are considering. These are the second level of assumptions that we make and are what are commonly referred to as models.
The function \(f\) is the output function that we want have learned from the data.
For example, a common family of functions \(F\) is linear i.e.
If we are trying to predict the temperature in Fahrenheit given the temperature in Celsius, then
where x is the input temperature in Celsius and f(x) is the output temperature in Fahrenheit.
The above is just an example and there exist many other families of functions that we can consider. These will be covered in Chapters 10-13.
8.2.1. Code Example#
The code below uses K-Nearest Neighbors (KNN) to learn the relationship between the features and the target variable.
The fit method is used to train the model. The fit method takes two arguments:
X_train- the features of the training datay_train- the target variable of the training data
The fit method learns the relationship between the features and the target variable and stores it in the model object.
The fit method is common to all models in sklearn and is used to train the model.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
MultinomialNB()
8.3. Testing Phase#
Once we have learned the function \(f\) from the training data, we can apply it to the test data to predict the target variable \(\mathcal{y}\).
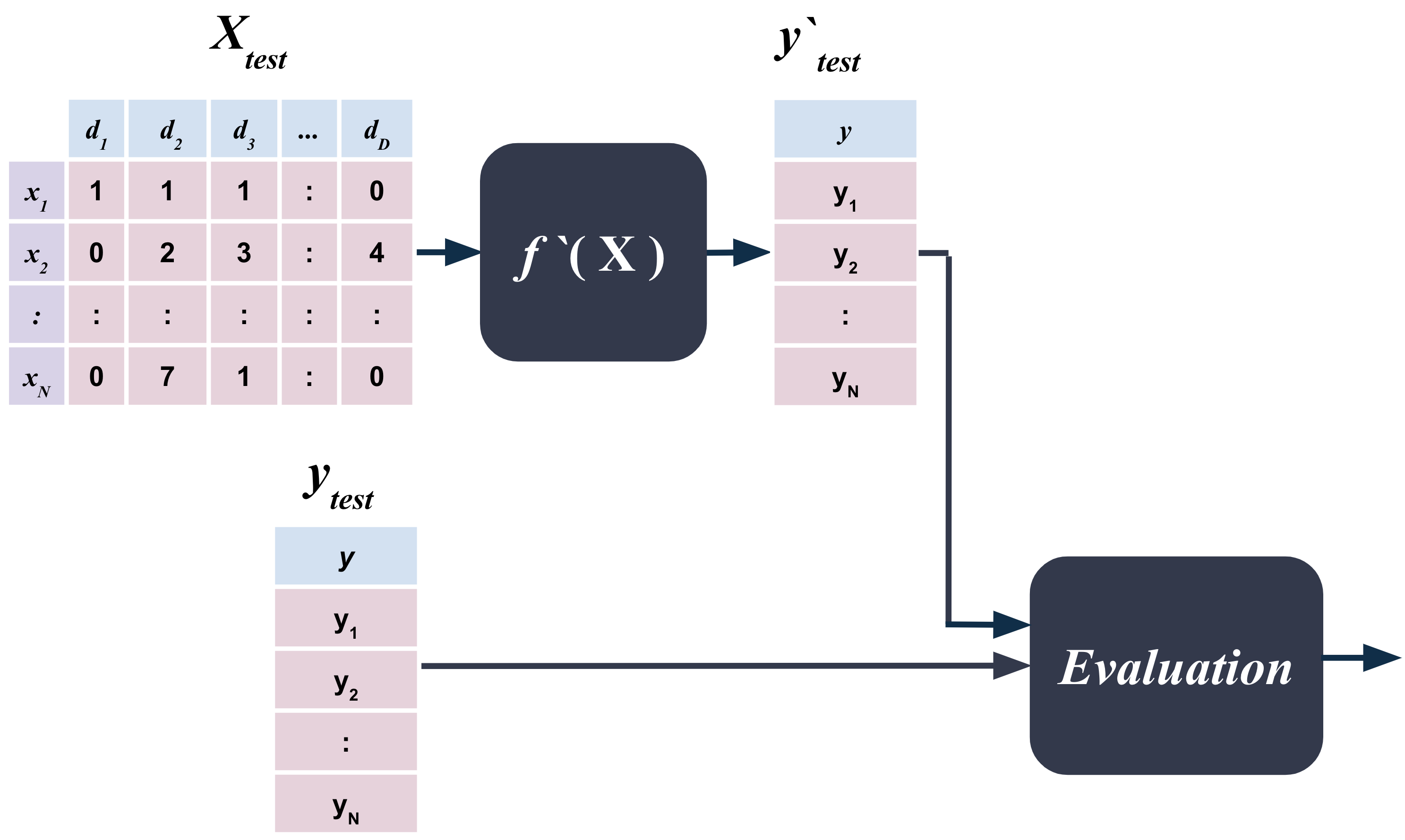
8.3.1. Code Example#
The code below uses the predict method to predict the target variable for the test data.
The predict method is used to test the model. The predict method takes one argument:
X_test- the features of the test data
The predict method applies the learned function \(f\) to the test data and returns the predicted target variable.
The predict method is common to all models in sklearn and is used to test the model.
preds = classifier.predict(X_test)
preds
array([1, 0, 2, 1, 1, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 2,
0, 2, 1, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 2, 1, 0])
8.4. Evaluation#
If supervised learning is like school, then the evaluation phase is like the grading phase and criteria.
The evaluation phase is where we evaluate how well we have learned the function \(f\) from the training data and how well we can predict the target variable \(\mathcal{y}\) from the test data.
The exact criteria for evaluation depends on the type of supervised learning problem. That is, evaluation metrics used for classification problems are different from those used for regression problems. These metrics are discussed in detail in the following chapters.
8.4.1. Code Example#
The code below uses the accuracy_score method to evaluate the performance of the model.
The accuracy_score method is used to evaluate the model. The accuracy_score method takes two arguments:
y_test- the actual target variable of the test datay_pred- the predicted target variable of the test data
The accuracy_score method compares the predicted target variable to the actual target variable and returns the accuracy of the model.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, preds)
0.9736842105263158
8.5. Cross Validation#
Just as most courses in school don’t have just the final test, most machine learning problems don’t have just one test set either. Often times, it is better to create multiple test sets, evaluate the performance of the model on each of them and then report the average performance of the model. This practice is called cross validation in machine learning.

There exist many different ways to create multiple test sets. The most common way is to randomly split the data into multiple randomly sampled train and test sets. This is called random cross validation.
8.5.1. Code Example#
The code below uses the cross_val_score method to perform random cross validation.
The cross_val_score method is used to cross validate the model. The cross_val_score method takes four arguments:
estimator- the model objectX- the features of the datay- the target variable of the datacv- the number of cross validation splits
The cross_val_score method performs random cross validation and returns an evaluation metric of the model for each split.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(classifier, X, y, cv=5, scoring='accuracy')
scores
array([1. , 0.96666667, 0.9 , 0.9 , 1. ])