3. Post-Training: Reinforcement Learning#

Once a model is trained on internet data, it still doesn’t know how to use its knowledge effectively.
Supervised fine-tuninsg teaches it to mimic human responses.
Reinforcement learning (RL) helps it improve by trial and error.
How RL Works#

Instead of relying on human-created datasets, RL lets the model experiment with different solutions and figure out what works best.
Example Process:
We generated 15 solutions.
Only 4 of them got the right answer.
Take the top solution (each right and short).
Train on it.
Repeat many, many times.
No human is involved in this process. The model generates different solutions to the same problem, sometimes they are in millions. Then it compares them to pick the ones that reached the correct answer and then trains on the winning solutions.
The pre-training and post-training processes are very well defined but the RL process is still under a lot of active research. Andrej talks about it here as well. Companies like OpenAI do a lot of research on it but it’s not public. That is why the release of DeepSeek was such a big deal. Their paper talks more about it. It talks very publicly about RL and FT for LLMs and how it brings out a lot of reasoning capabilities in them.
An example taken from the Deepseek paper shows us that as the time passes, the model is able to use more tokens to get better at reasoning.

You can see that the model has this “aha” moment here, it’s not something that you can explicitly teach the model through just training on a dataset. It’s something that the model has to figure out on it’s own through reinforcement learning. Pros of this technique is, the model is becoming better at reasoning but the con is it’s consuming more and more tokens to do so.
One thing we can learn from the research paper on mastering the game of Go is that RL actually helps the model become better at reasoning than their human counterparts. The model isn’t just trying to imitate the human but it’s coming up with its own strategies through trial and error to win the game.
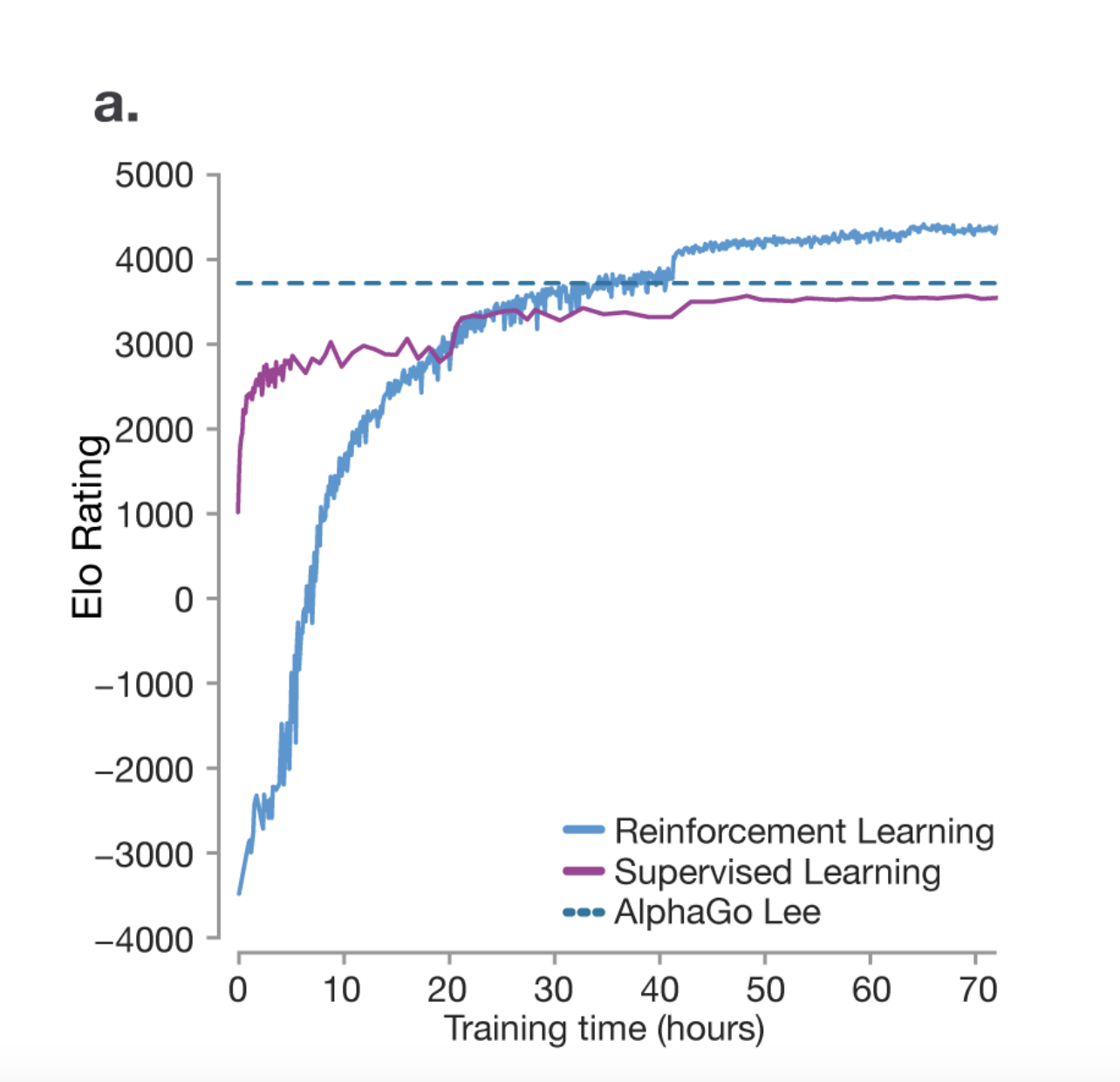
One very unique thing noted during the AlphaGo’s game was a move called Move 37. It’s a move that was not part of the training data but the model came up with its own strategy to win the game. The researchers predicted that the chance of it being played by a human would be 1 in 10000. So you can see how the model is capable of coming up with its own strategies.
RL is still heavily unexplored and there is a lot of research going on in this area. It is entirely possible if given the chance, the LLM might come up with a language of its own to express its thoughts and ideas because it discovered that it’s the best way to express its thoughts and ideas.
Learning on unverifiable domains a.k.a Reinforcement Learning from Human Feedback (RLHF)#
It is very easy to exclude humans from the RL process in verifiable domains. LLMs can act as a judge for its own performance.
However, in unverifiable domains, we need to include humans in the loop.
For example, for a prompt Write a joke about pelicans, it is not very easy to find a way to automatically judge the quality of the joke. The LLM will generate the jokes without issues, but judging their quality at scale is not possible.
Furthermore, including humans in this process at scale is not feasible. This is where RLHF comes in. You can read more about it in this paper.

In order to do RLHF at scale, you basically train a separate reward model which could be a transformer without the extra layers surrounding it. You use humans to judge the rank it is giving to the responses and then you use that to train the reward model until you are satisfied with the results. Once that is done, you can use the reward model to judge the quality of the responses generated by the LLM at scale.

RLHF Upside
Enables RL in unverifiable domains like joke-writing or summarization.s
Often improves models by reducing hallucinations and making responses more human-like.
Exploits the “discriminator-generator gap”—humans find it easier to evaluate an answer than generate one.
Example: “Write a poem” vs. “Which of these 5 poems is best?”
RLHF Downside
The reward model is just a simulation of human preferences, not an actual human. This can be misleading.
RL can game the system, producing adversarial examples that exploit weaknesses in the reward model.
Example: After 1,000 updates, the model’s “top joke about pelicans” might be complete nonsense (e.g., “the the the the the the the the”).
This is known as Adversarial Machine Learning. Since there are infinite ways to game the system, filtering out bad responses isn’t straightforward.
To prevent this, reward model training is capped at a few hundred iterations—beyond that, models start over-optimizing and performance declines.